
Agentic AI Tech Stack Explained
The 7 Layers Under Every Production Agent, What Lives in Each, and Where Teams Actually Get Stuck

Most teams have a model and a framework and call that “the stack.” It isn’t. The reason your agent works in the demo and crashes in production is almost always a missing layer underneath.
The agentic AI hype cycle has trained a generation of builders to think the “stack” is whatever framework they’re using on top of whatever model they’re paying for. That worked for prototypes. It breaks the moment real users show up. A production-grade agent has seven layers under it, each solving a problem the layer above takes for granted, and the teams shipping reliable agents in 2026 are not the ones with the cleverest prompts. They are the ones with the most complete stack.
This post lays out all seven layers, the tools that actually live in each one, the buy-versus-build calls that matter, and the anti-patterns that quietly turn six-week projects into six-month rewrites.
Index
The Stack at a Glance: Why Agentic Systems Need Seven Layers, Not Two
Layer 1, The Model Layer: Frontier APIs, Open Source, and Why You Want a Gateway From Day One
Layer 2, Memory and Retrieval: The Difference Between a Smart Agent and a Useful One
Layer 3, Tools and Integrations: How MCP Quietly Became the USB-C of Agents
Layer 4, Orchestration: The Layer Everyone Overweights and the One Place Frameworks Live
Layer 5, Runtime and Execution: Sandboxes, Durable Execution, and Why Production Agents Crash
Layer 6, Observability and Evals: The Layer That Decides Whether You Actually Know Anything
Layer 7, Safety and Guardrails: The Cross-Cutting Layer Nobody Buys Until It’s Too Late
The Five Buy-vs-Build Decisions That Actually Matter
Linkstash: Tools and Docs by Layer
The Stack at a Glance: Why Agentic Systems Need Seven Layers, Not Two
The whole stack in one picture. Five layers sit in the request path. Two cross-cutting layers wrap everything else
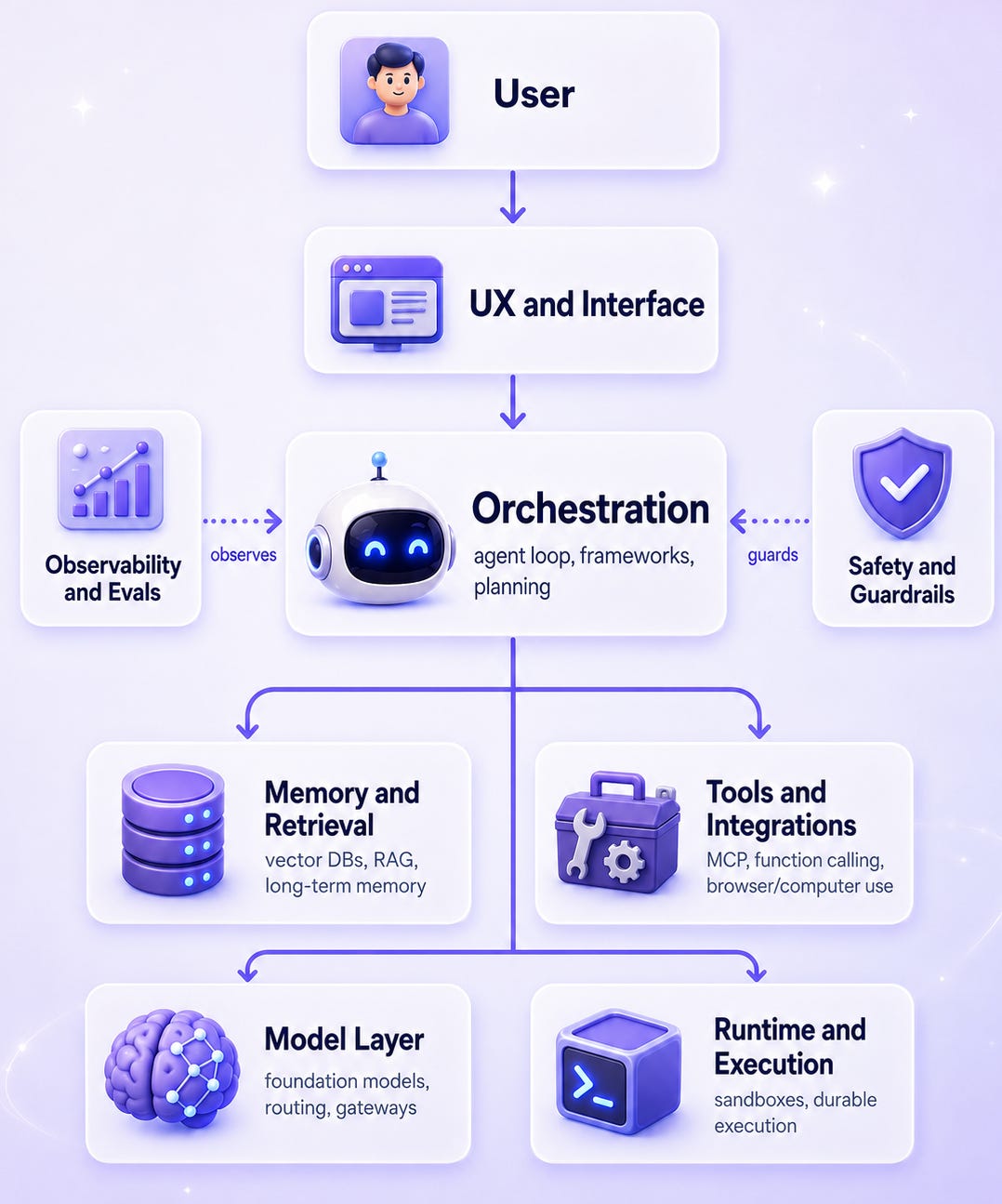
Two things to notice. First, the orchestration layer is the only one most teams discuss, and it’s the smallest box on this diagram. Second, when production agents fail, the failure almost always lives at a layer boundary, not inside any one layer. “The agent forgot what we discussed” is a memory layer failure. “It hallucinated a tool call” is a tools layer failure. “It crashed at minute 28” is a runtime layer failure. Naming the layer is half the fix.
Layer 1, The Model Layer: Frontier APIs, Open Source, and Why You Want a Gateway From Day One
The brain layer. Three sub-categories matter in 2026.
Frontier APIs (Anthropic, OpenAI, Google) for the hardest reasoning, longest context, and strongest tool-use behavior. Open-source models (Llama, Qwen, DeepSeek, Mistral, Gemma) self-hosted via vLLM, SGLang, or TGI for cost-sensitive or data-sensitive workloads. Hosted enterprise (Bedrock, Vertex AI, Azure OpenAI) when you need the frontier inside your cloud account with compliance.
The non-obvious move is to sit a gateway in front of whichever model you use. LiteLLM, Portkey, OpenRouter, and Helicone all give you one API surface that abstracts over providers.
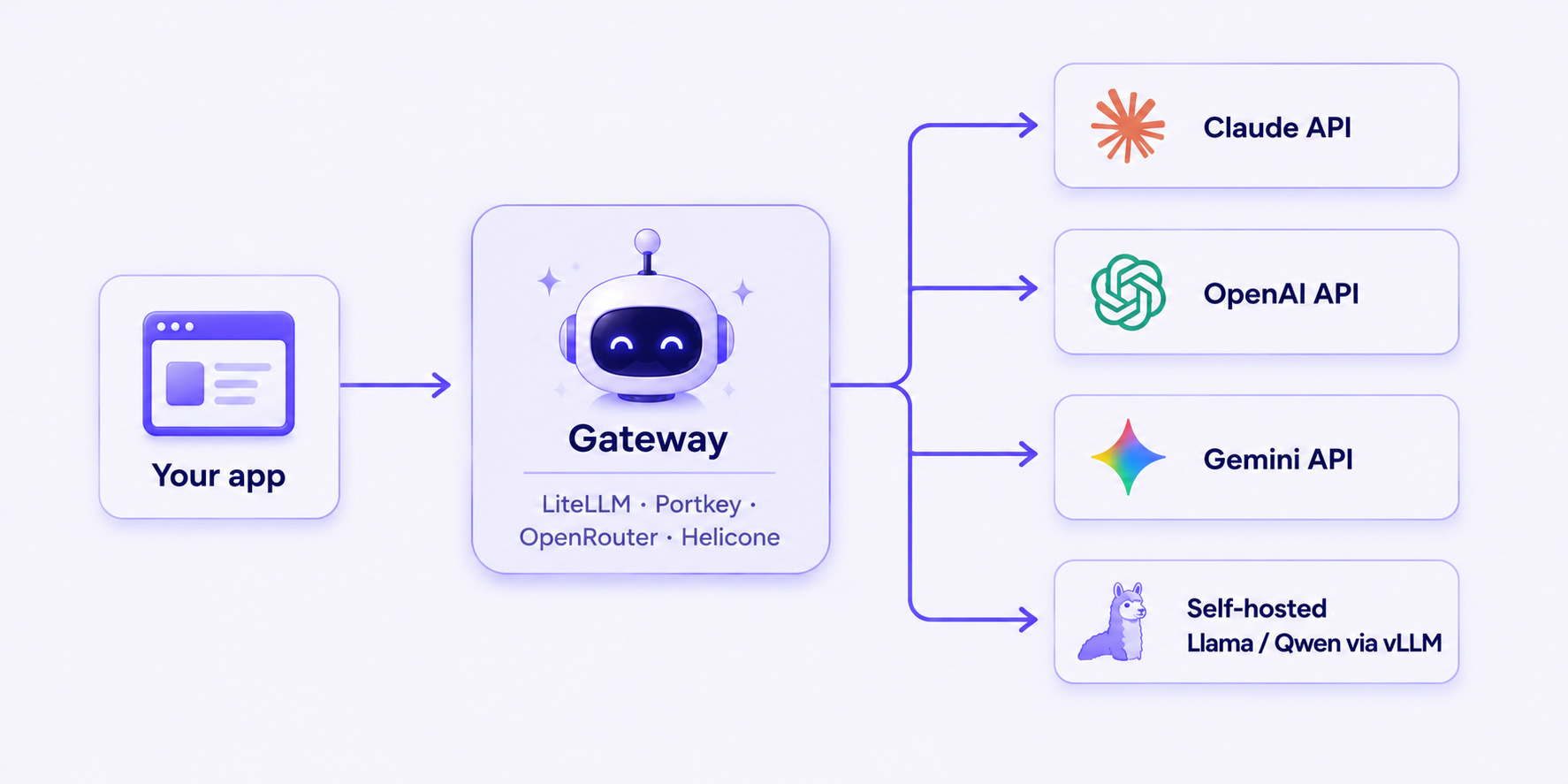
Why early. Provider outages happen. Per-task model routing (cheap model for easy turns, frontier for hard ones) is a real cost lever. And consolidated logging across providers is impossible to add later. Gateways are a five-minute install that saves a four-week migration later.
Layer 2, Memory and Retrieval: The Difference Between a Smart Agent and a Useful One
A model with no memory is a goldfish with a vocabulary. The memory layer has two parts and a bridge between them.
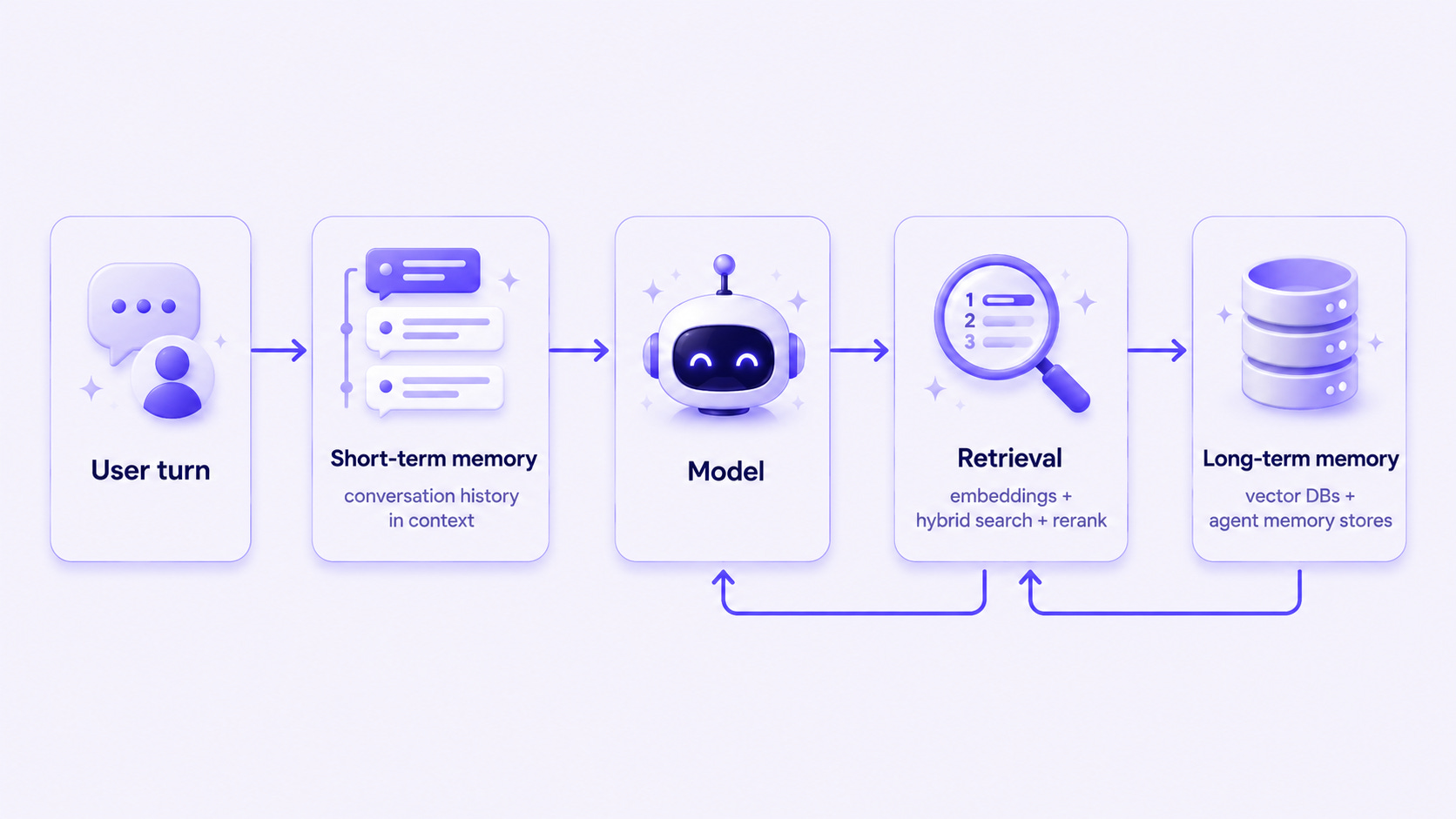
Short-term memory is the conversation history that fits in the context window. Long-term memory is everything else: documents, past sessions, user preferences, learned facts. The dominant storage option is still vector databases(Pinecone, Weaviate, Qdrant, Chroma, pgvector, Milvus), but the interesting 2026 shift is the rise of purpose-built agent memory layers like Mem0, Zep, and Letta, which handle the “what should I remember about this user across sessions” problem that raw vector stores never really did.
The other quiet shift: pure vector retrieval is no longer state of the art. Hybrid retrieval (semantic plus keyword) combined with a reranker (Cohere Rerank, BGE rerankers, Voyage rerank) beats vector-only on basically every benchmark and most real workloads. If your RAG quality is plateauing, this is the most likely fix.
I have some great news to share! We were just featured as MAVEN 100, and to celebrate that we are giving a discount on the course.
I am hosting a 6-week Mastering Agentic AI Certification with my co-founder Arvind Narayan, to help you build the skills and system-level understanding needed to become the top 0.1% of AI experts.
This is not just for builders or engineers. In today’s AI landscape, being “technical” is no longer optional, even if you are in product, product marketing, GTM, sales, or partnerships. You don’t need to write code every day, but you do need to understand how these systems work.
The idea of being a builder has also become far more accessible. With the range of no-code and low-code tools available today, you can build real agentic workflows and automations without being an engineer.
In 6 weeks- we will be covering GenAI foundational concepts, RAG systems, Agentic AI Design patterns, Fine-tuning, AI evaluations, and AI security/ safety.
There are no pre-req for the course, in our current cohort- we have >35% people from non-coding background! We will be teaching you deep-technical concepts and help you become a “builder”. Every week you will be building a project. There are 2 tracks for the project- low code/no-code for non-developers, and code-heavy for developers.
Special discount for my Substack family: https://maven.com/aishwarya-srinivasan/mastering-ai-agents?promoCode=MAVEN100
Layer 3, Tools and Integrations: How MCP Quietly Became the USB-C of Agents
This is the layer where the agent stops being a chatbot and starts acting on the world.
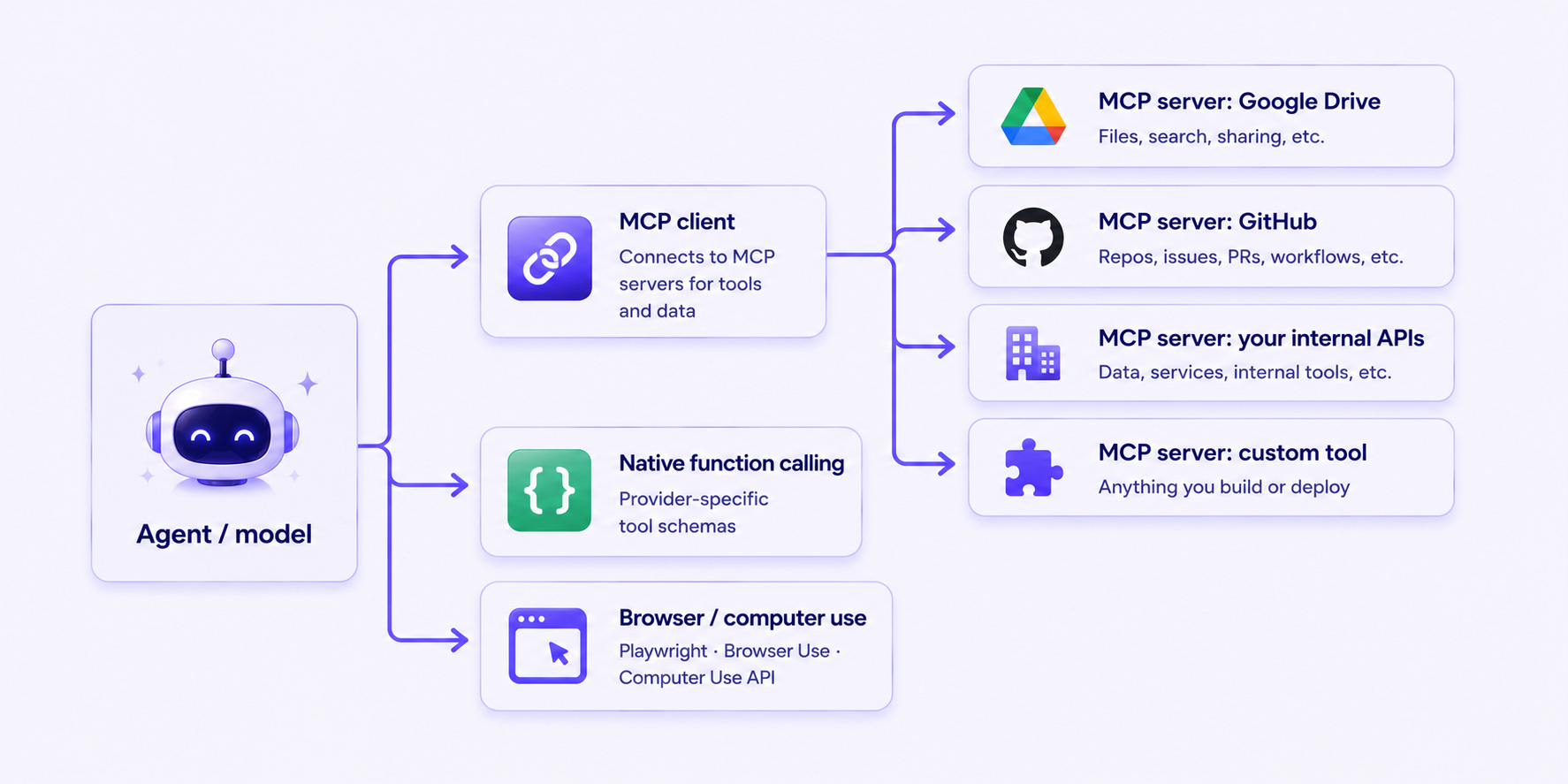
Three categories of tool access. Native function calling is the provider’s built-in tool-use schema (works great, but couples your tools to one model family). Browser and computer use is for tasks with no API: Playwright, Browser Use, and Anthropic’s Computer Use let agents drive a real browser or desktop. And in the middle, the big 2026 story, is MCP (Model Context Protocol).
MCP standardized how agents discover and call tools. Servers expose tools (with schemas and auth); any MCP-aware client can call any server. Tools used to be tightly coupled to your framework. Now they’re a protocol, and the directories (mcp.so, official server lists) have thousands of pre-built integrations. If you’re picking a tools strategy in 2026, default to MCP unless you have a specific reason not to.
Layer 4, Orchestration: The Layer Everyone Overweights and the One Place Frameworks Live
Orchestration is the agent loop itself. Decide what to do next, call a tool, observe the result, decide again.
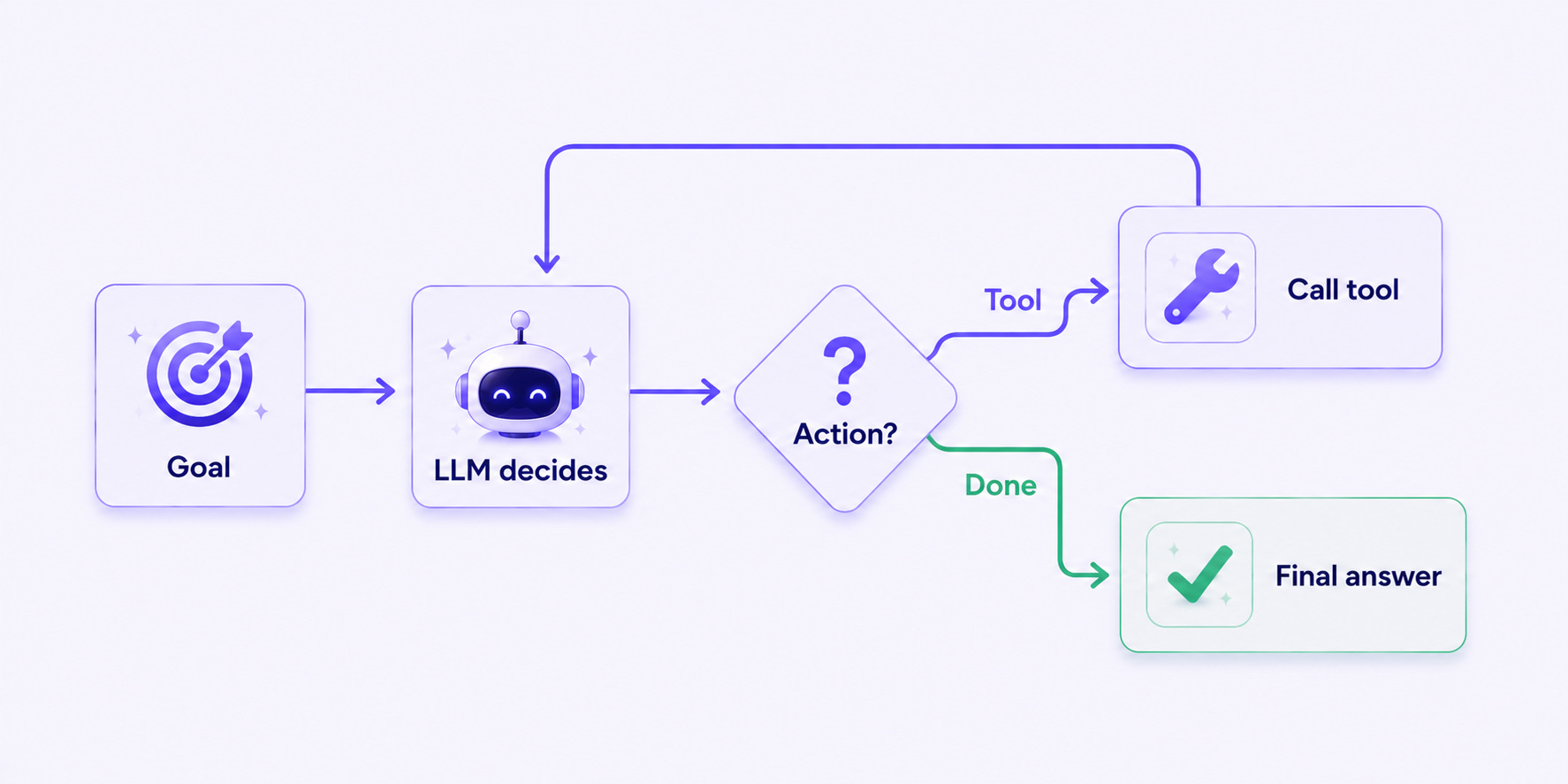
This is where agent frameworks live. LangGraph for complex stateful flows. OpenAI Agents SDK for lightweight Python on OpenAI-first stacks. Pydantic AI for type-safe production. CrewAI and AutoGen for genuine multi-agent setups. Mastra and the Vercel AI SDK for TypeScript stacks. Smol Agents or direct API calls if you want to keep abstractions minimal.
The honest critique of this layer: most teams overspend their attention here. The framework is plumbing. Picking the wrong one costs you a refactor. Picking the wrong memory or observability layer costs you a customer.
