
Architecting Next-Gen AI with Multi-Agent Systems
Most teams are still treating ML models like one-off scripts, particularly with LLMs. One prompt in, one output out. On repeat. And yet, the true frontier for scaling AI systems to real-world autonomy isn't in isolated LLM calls, but in the sophisticated orchestration of multiple, specialized agents working in concert.
In this blog, I break down how multi-agent architectures are becoming essential for building AI systems that go beyond superficial interactions and actually exhibit complex reasoning, planning, and execution. This is where performance, reliability, and true autonomy converge.
Why Multi-Agent Architectures Matter More Than Ever in LLM Applications
The rapid advancements in Large Language Models (LLMs) have given us unprecedented capabilities in natural language understanding and generation. However, single-instance LLMs, while powerful, often struggle with tasks requiring extensive long-term memory, complex multi-step reasoning, dynamic tool use, or robust error handling in open-ended environments. These limitations become glaring as we push towards building truly autonomous AI systems that can operate in dynamic, real-world scenarios.
Recent industry trends in agentic AI development—from frameworks like LangChain, AutoGen, and CrewAI to the emergence of communication protocols like Agent Communication Protocol (ACP)—signal a decisive shift. Organizations are increasingly piloting and implementing multi-agent systems to tackle problems beyond the scope of a solitary LLM. This evolution allows for several critical advantages, including complex task decomposition by breaking down grand challenges into smaller, manageable sub-problems. It also enhances robustness by distributing intelligence and capabilities across multiple components, thereby mitigating single points of failure. Furthermore, multi-agent systems offer superior scalability and modularity, enabling extensible systems where new capabilities can be added by introducing new agents or tools without re-architecting the core. Finally, observing the interaction patterns and division of labor among agents can provide clearer insights into the system's decision-making process, improving interpretability.
To truly unlock the potential of AI beyond simple "copilots," senior AI engineers are actively implementing sophisticated multi-agent design patterns. These patterns provide the architectural blueprints for coordination, communication, and collective intelligence.
The Six Pillars of Multi-Agent LLM System Design
Building production LLM systems that handle complex, real-world tasks requires multiple specialized agents working in concert. After years of experimentation across the industry, six distinct patterns have emerged as the workhorses of multi-agent design. These patterns solve real problems in production environments, each with specific strengths and trade-offs worth understanding deeply.
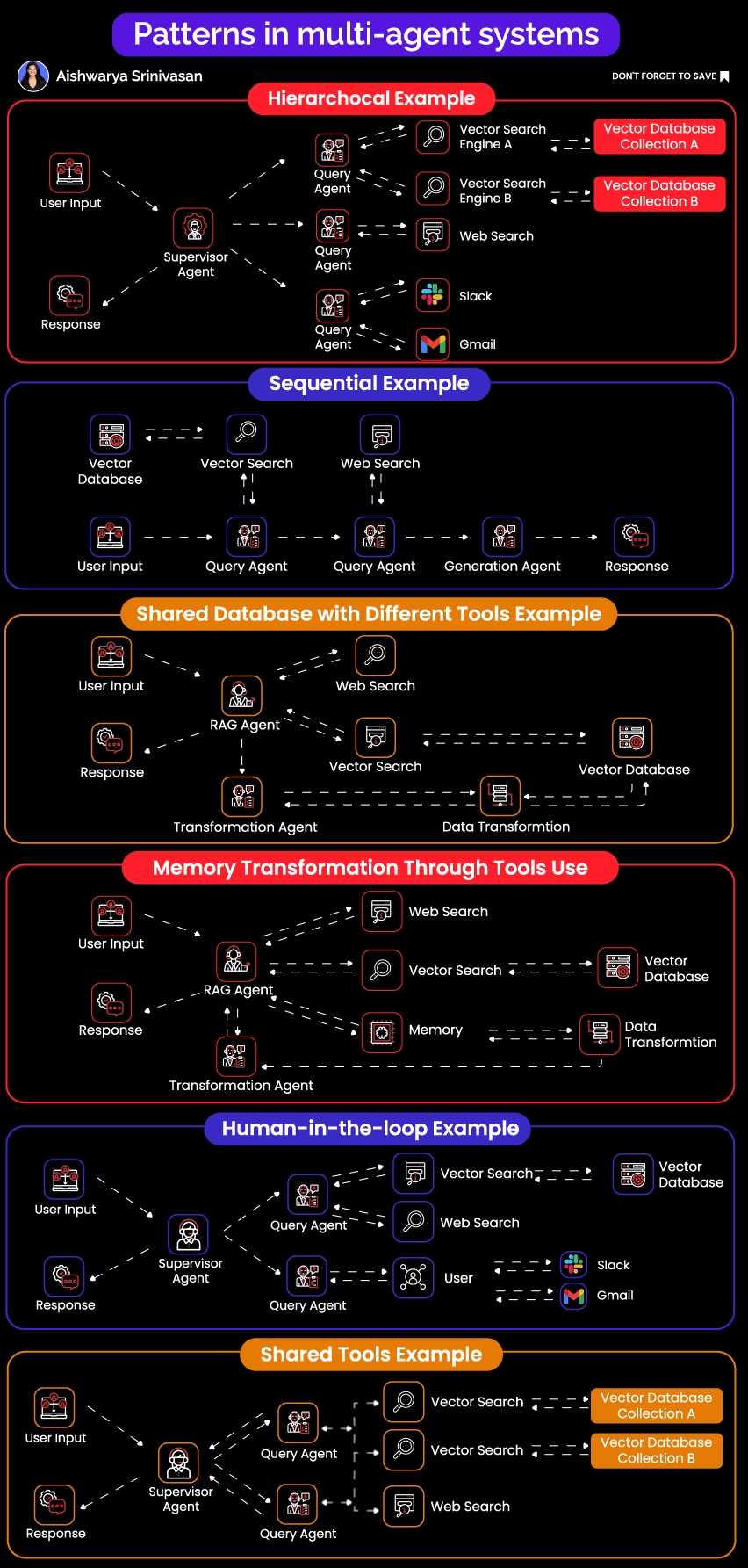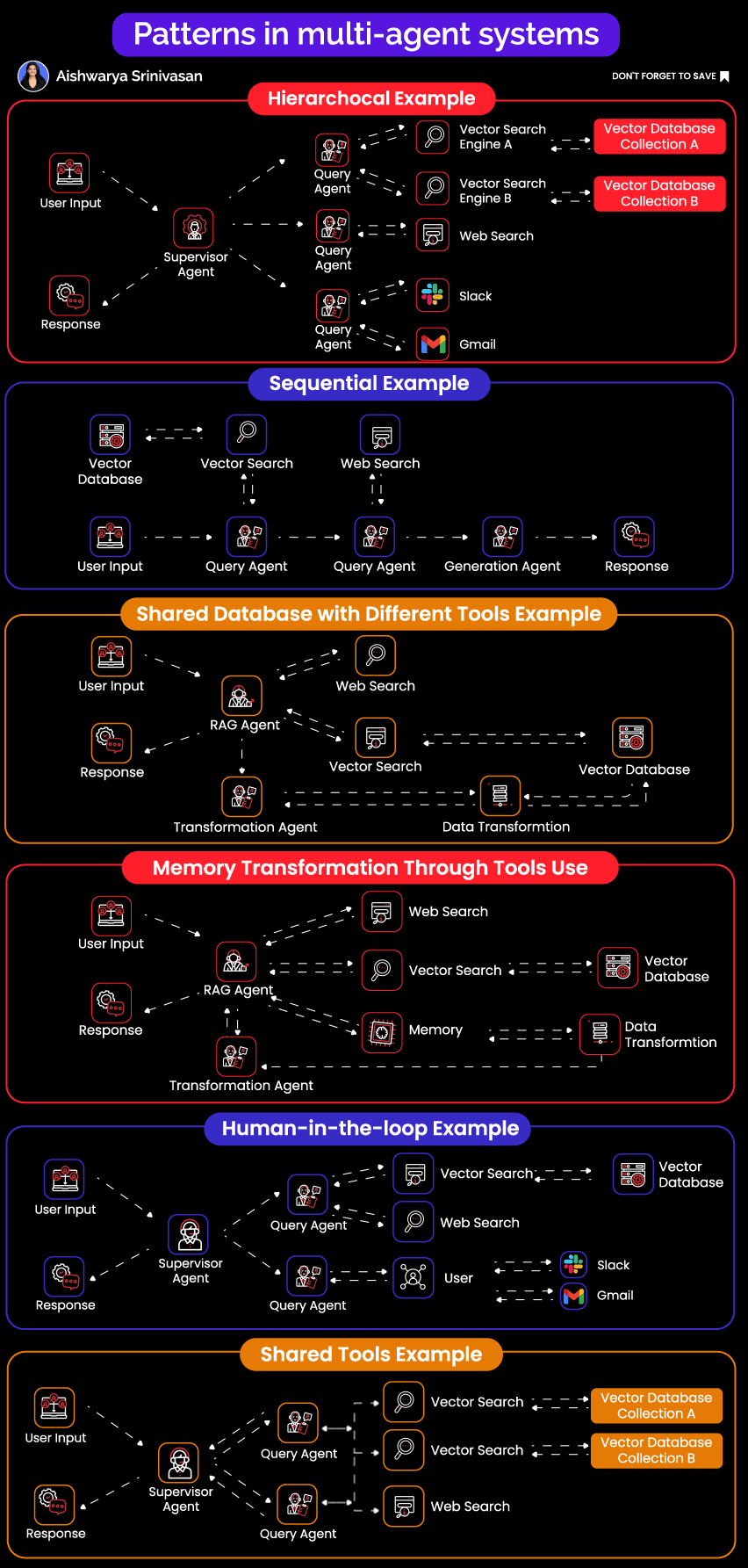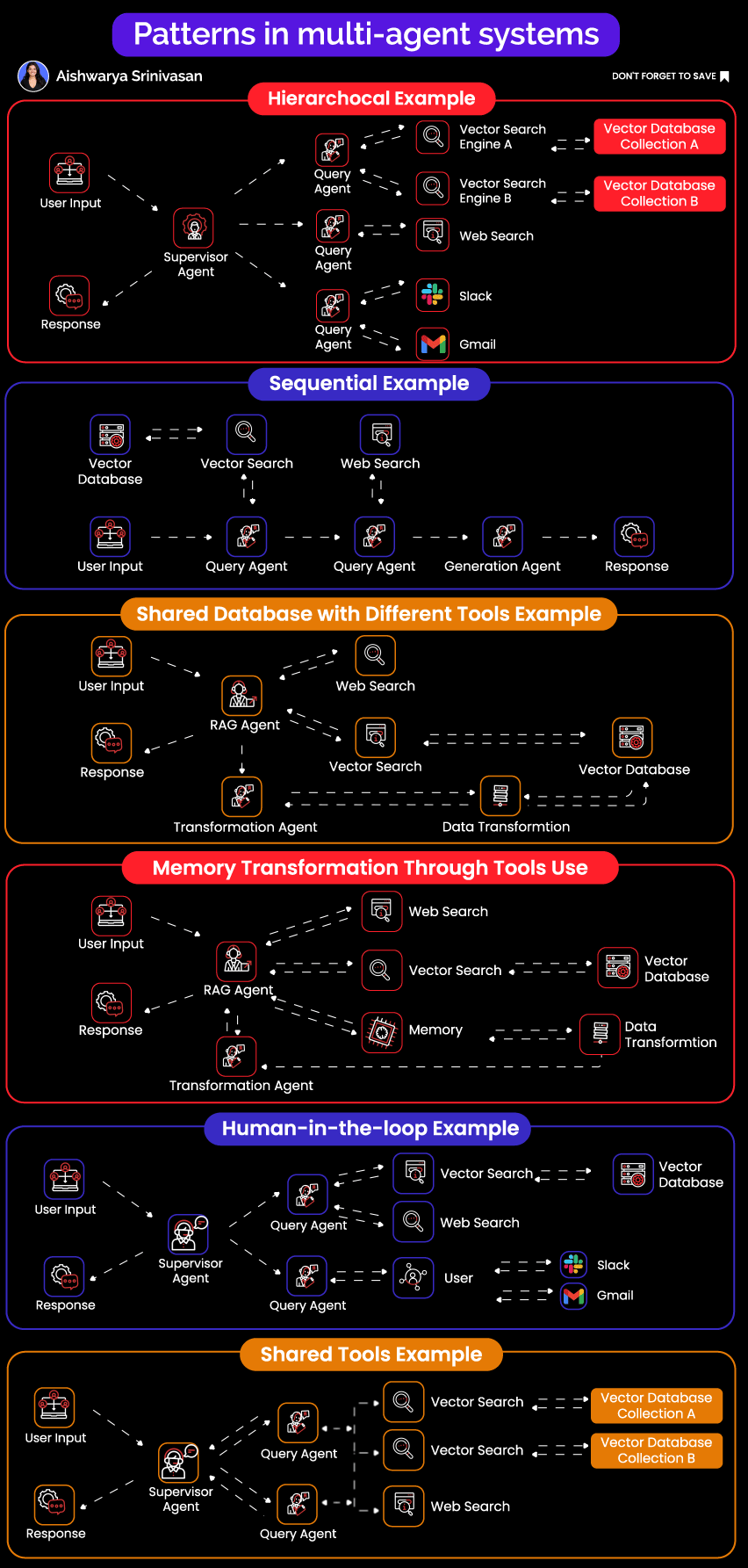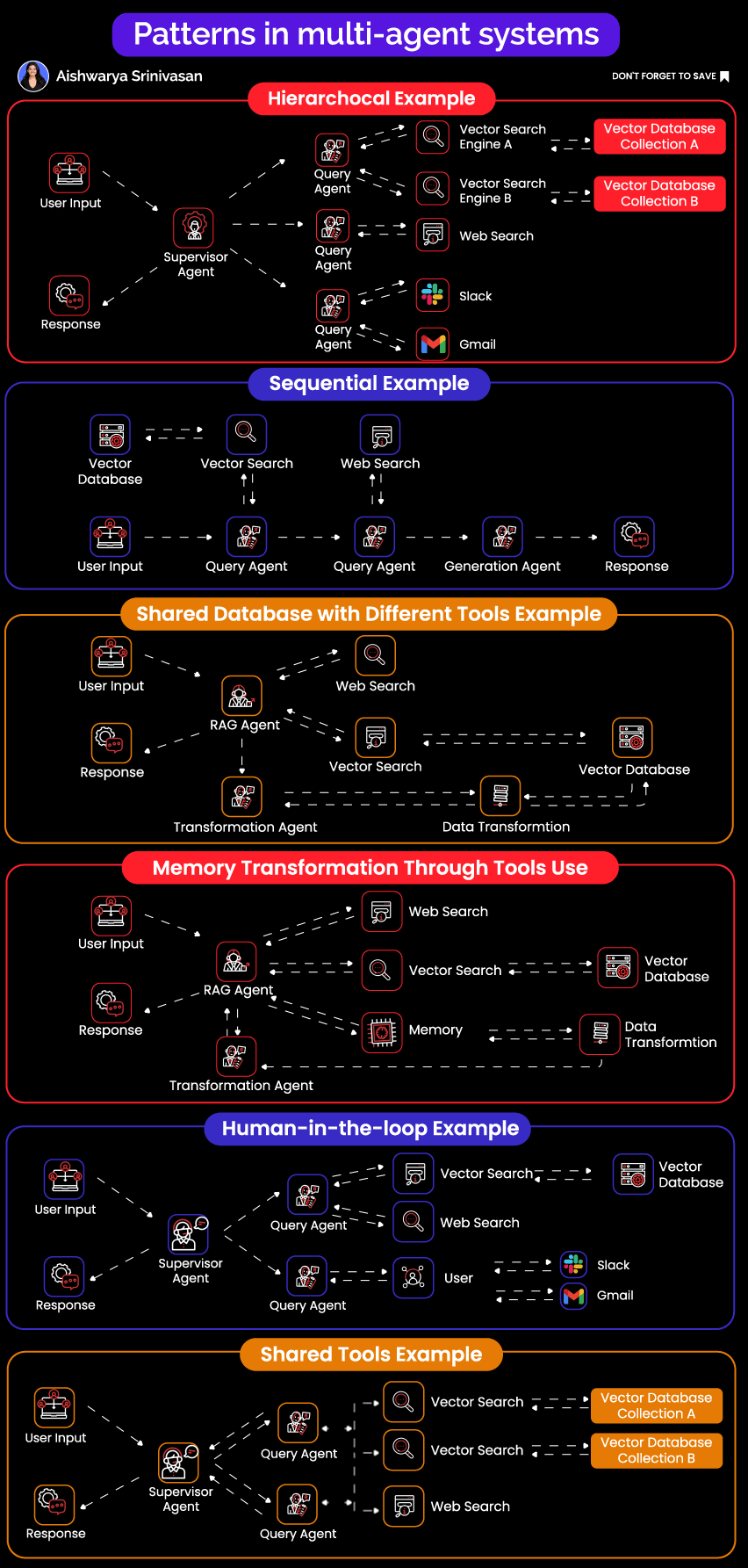
1. Hierarchical Agent Networks
The Pattern: A master planner agent acts as an intelligent orchestrator, decomposing complex tasks into manageable subtasks and delegating them to specialized sub-agents. This mirrors how effective engineering teams operate, with a technical lead breaking down projects and assigning work to specialists.
Real Example: Consider a market research system analyzing competitive landscapes. When the orchestrator receives a request to "analyze competitor pricing strategies in the SaaS analytics space," it doesn't try to handle everything itself. Instead, it creates a structured execution plan:
A web research agent first identifies the top 20 competitors using search APIs and industry databases
A specialized scraping agent then extracts detailed pricing data from each competitor's website
A data transformation agent normalizes wildly different pricing models (per-seat, usage-based, tiered, hybrid)
Finally, an analysis agent identifies patterns, outliers, and generates strategic insights
Each specialist agent operates with custom prompts tailored to its domain, specialized tools relevant to its task, and domain-specific error handling that understands what failures mean in context.
Key Implementation Details:
Correlation IDs: Every request generates a unique identifier that flows through all layers. When debugging production issues at 2 AM, being able to trace a request through multiple agent layers becomes invaluable.
Health monitoring: Each agent reports its status every 30 seconds to a central monitor. Dead agents trigger automatic restarts, and persistent failures escalate to ops teams.
Intelligent timeouts: Parent agent timeouts equal the sum of expected child execution times plus a 20% buffer. This prevents premature failures while still catching stuck processes.
Error boundaries: Failures in one branch don't automatically kill the entire task tree. The parent agent can often proceed with partial results.
Result aggregation strategies: Parent agents need sophisticated logic for handling mixed success/failure scenarios from children.
Watch Out For: The biggest gotcha in hierarchical systems is silent failures deep in the tree. A corruption three layers down might only manifest as slightly wrong results at the top, making debugging extremely difficult. Comprehensive logging and monitoring at every level is non-negotiable. Communication overhead also grows exponentially with depth, so keeping hierarchies shallow (three levels maximum) tends to work best. Circuit breakers become essential to prevent cascading failures from rippling through the entire tree.
2. Sequential Processing Pipelines
The Pattern: Taking inspiration from Unix philosophy, each agent does exactly one thing well and pipes its output to the next agent in the chain. The beauty lies in its simplicity: clear data flow, predictable behavior, and easy debugging.
Real Example: A document processing pipeline that handles thousands of documents daily might look like this:
OCR agent converts scanned PDFs and images to text using Tesseract for simple documents and Cloud Vision for complex layouts
Format normalizer takes Word documents, PDFs, HTML, and even email formats, converting everything into a consistent JSON structure
Entity extractor identifies and pulls out names, dates, monetary values, addresses, and domain-specific entities
Validation agent cross-references extracted data against existing databases, checking for consistency and flagging anomalies
Report generator creates final output in whatever format downstream systems expect
The critical insight: each handoff between agents uses strict schema validation through Pydantic models. When data doesn't match the expected schema, the pipeline fails immediately and loudly rather than propagating corrupted data downstream.
Key Implementation Details:
Contract testing: Every agent publishes its input/output schemas. Automated tests verify that connected agents have compatible contracts.
Metadata sidecars: A parallel metadata object travels alongside the main data, tracking confidence scores, processing timestamps, data lineage, and any warnings generated.
Comprehensive observability: Each pipeline stage emits detailed metrics including processing latency, error rates, throughput, and queue depths.
Smart retry logic: Transient failures trigger exponential backoff with jitter to prevent thundering herds. Different error types get different retry strategies.
Dead letter queues: After maximum retry attempts, failed documents go to a dead letter queue for manual investigation rather than being silently dropped.
Watch Out For: The rigid structure that makes pipelines reliable also makes them inflexible. Adding conditional logic often requires architectural gymnastics. One team had to bolt on an entire "router" agent when business requirements changed to need different processing paths for invoices versus contracts. Upstream errors inevitably cascade downstream unless you implement strict validation gates between stages. Version mismatches between agents can cause subtle bugs that only appear under specific conditions, making semantic versioning and compatibility matrices essential.
Keep reading with a 7-day free trial
Subscribe to AI with Aish to keep reading this post and get 7 days of free access to the full post archives.