

Introduction
In 2025, AI agents are no longer science fair demos or proof-of-concepts, they’re expected to behave deterministically, perform complex sequences of reasoning, and interact with APIs, tools, and humans in high-stakes environments. From enterprise automation to developer copilots and vertical-specific assistants, AI agents are increasingly embedded into mission-critical workflows.
But while LLMs have evolved rapidly, the surrounding agent infrastructure often lags behind- resulting in brittle systems that fail silently, scale poorly, or hallucinate tools under load. Deploying agentic AI systems in production environments requires a full-stack engineering approach that is modular, introspectable, fault-tolerant, and built with real-world usage patterns in mind.
This post outlines a deeply technical, production-grade architecture for AI agents. It consolidates best practices from engineering leaders at the forefront of multi-agent systems, recent developments in orchestration frameworks, and lessons learned from operationalizing LLMs in high-load environments.
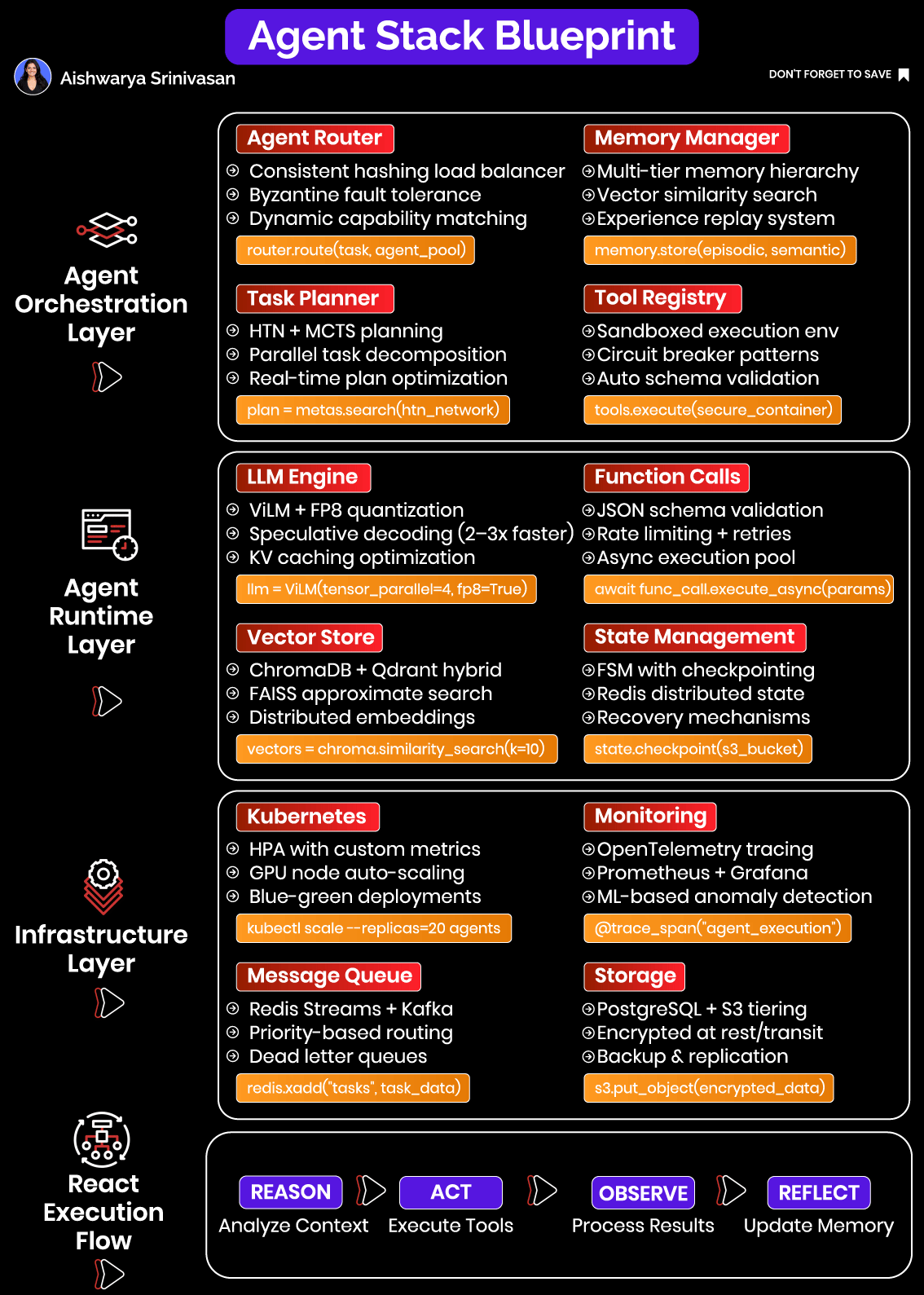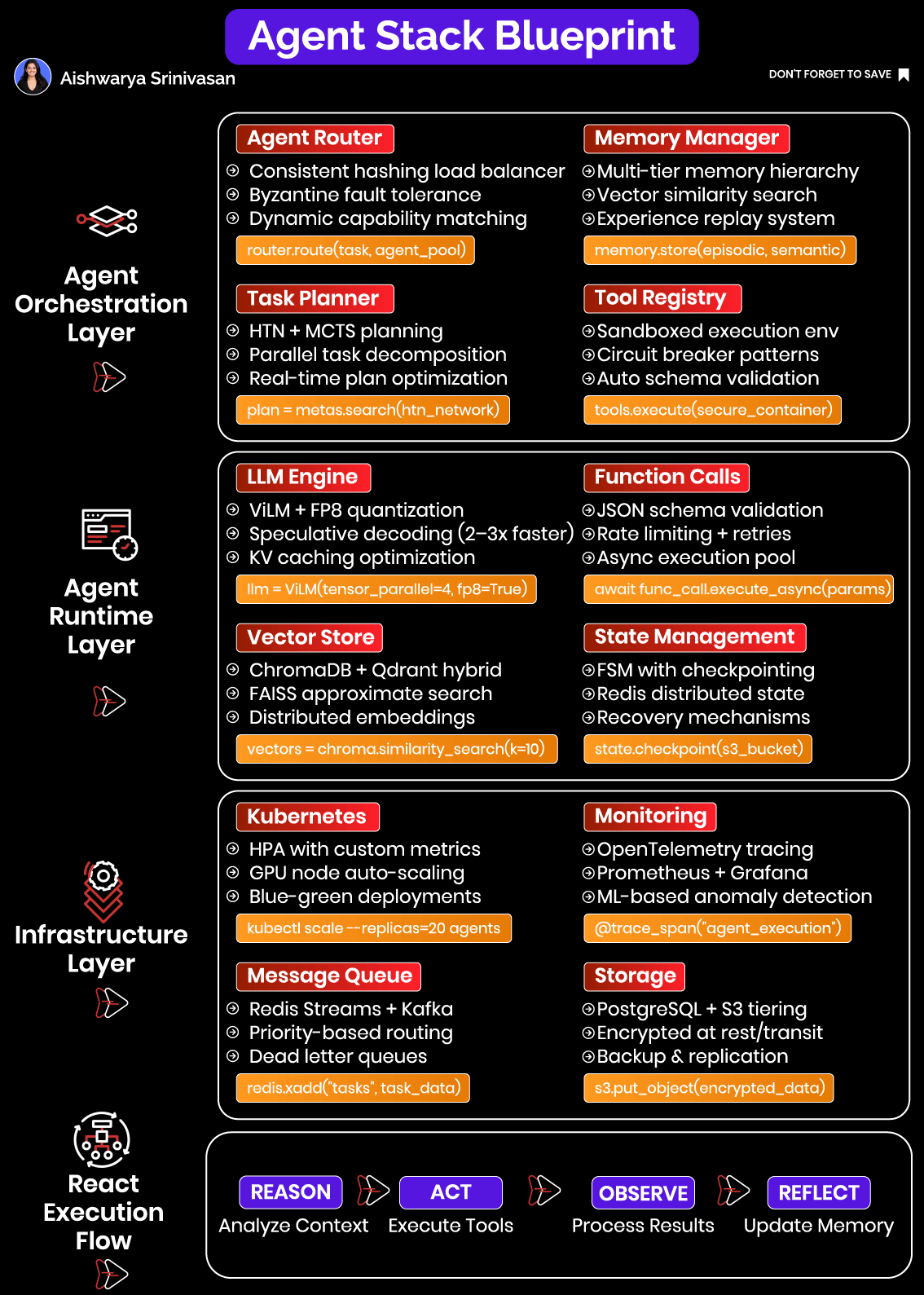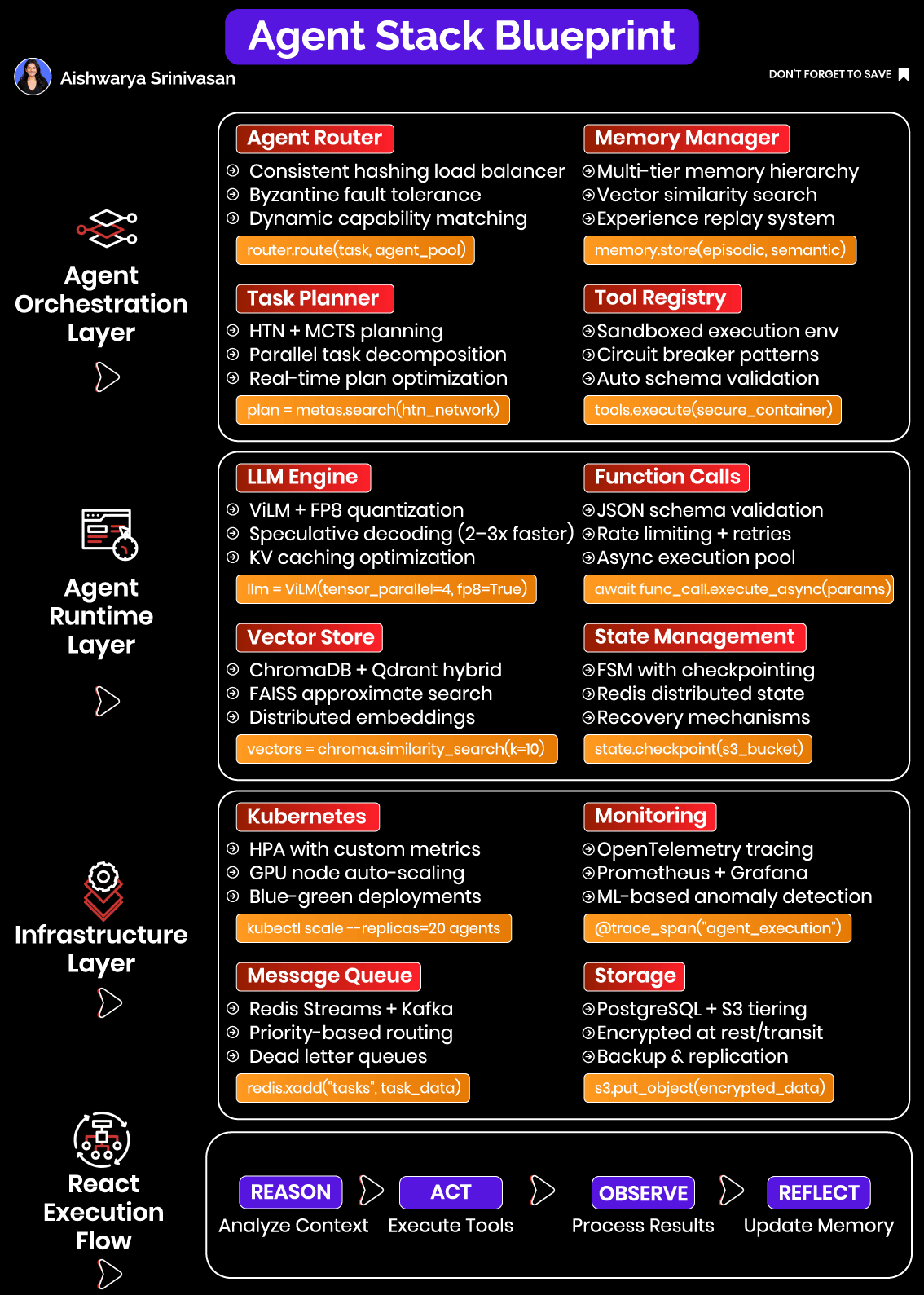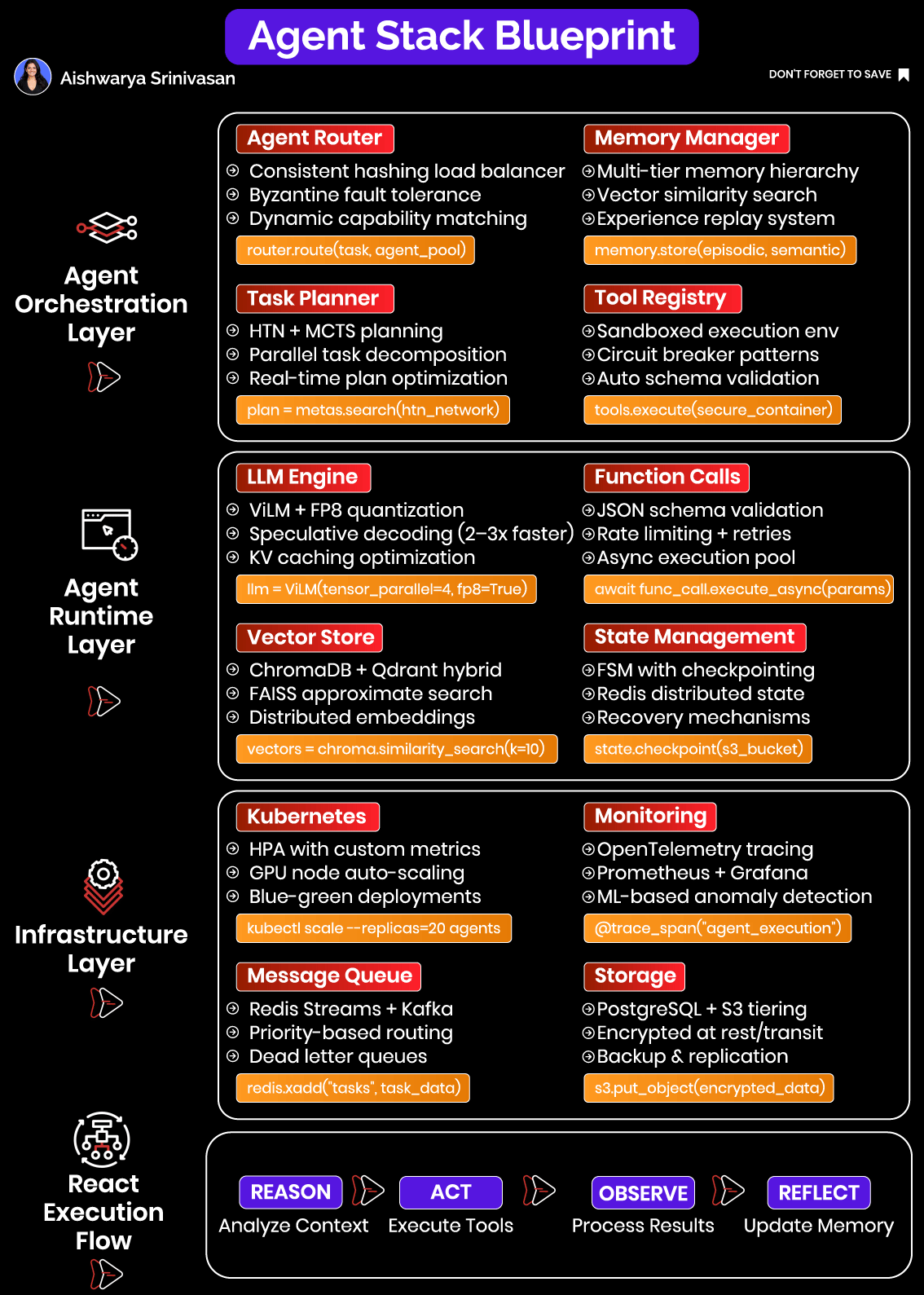
The Systems Mindset: Why a Modular Full-Stack Architecture is Required
From an engineering perspective, an AI agent in production is a stateful, distributed reasoning system. It must emulate the behavior of an intelligent assistant: breaking down goals, remembering prior context, invoking external tools, and adjusting to failures.
Let’s break this down through six interconnected subsystems:
Routing – Directs each task to the appropriate agent instance, preserving context and ensuring load balance across deployments.
Planning – Decomposes complex user goals into actionable and logically ordered subtasks. Ensures each action adheres to domain constraints.
Memory – Stores both short-term (session-specific) and long-term (knowledge or user preference) data. Memory is essential for personalization, continuity, and reasoning.
Runtime Execution – Coordinates the LLM inference, invokes tools, manages asynchronous operations, and captures intermediate results.
Infrastructure – Handles deployment, autoscaling, GPU utilization, and fault tolerance. Allows the system to respond elastically under variable load.
Observability – Makes the system introspectable across time and components. Enables engineers to monitor, debug, and improve agent behavior.
These components must interlock tightly. A memory failure upstream can cause incorrect tool calls; poor routing can break continuity and cause session resets; lack of observability leads to silent degradation in accuracy. The engineering mindset must shift from "calling an LLM" to designing a thinking, acting system with memory and environment awareness.
1. Orchestration Layer: Agent Composition, Routing, and Planning
🔁 Routing: Deterministic Task-to-Agent Assignment
In production systems, agents are typically deployed as stateful services. For continuity, each user or session should be routed to the same agent instance across turns.
Technical Objective: Maximize context retention, minimize cold starts.
Implementation Details:
Consistent Hashing over a unique session key enables deterministic routing. This is especially critical for memory-augmented agents.
Sticky Sessions can be persisted in Redis or tracked via sidecar proxies in service meshes (e.g., Istio).
Priority Queues are essential to differentiate urgent tasks from background operations. This reduces tail latency for high-value tasks.
Common Pitfalls:
Without proper task deduplication, duplicate agent instances may be spawned, leading to increased costs and inconsistent state.
Stateless routing may cause models to re-ingest context repeatedly, inflating token usage.
Recommended Tooling:
→ Redis, HashRing, Linkerd, Kafka with consumer groups, Celery with priority queues.
🧠 Planning: Structured Task Decomposition and Path Optimization
Planning enables agents to handle multi-step tasks that require conditional logic, ordering constraints, and fallback mechanisms.
Goal: Decompose high-level intents (e.g., “Plan my Paris trip”) into a DAG of sub-tasks that can be executed deterministically or with adaptive branching.
Planning Strategies:
Hierarchical Task Networks (HTNs): Define goals and permissible decompositions. Suitable for domains with symbolic structures.
Execution DAGs: Represent dependencies between subtasks. Enables rollback or parallel execution.
Monte Carlo Tree Search (MCTS): Useful for dynamically selecting actions under uncertainty.
Planning Output:
Each subtask is annotated with preconditions, postconditions, time estimates, and failure modes.
Execution plans must support partial success and recovery.
Open Source Tools:
→ PyHOP (HTNs), PDDL+pyperplan (symbolic planners), OpenSpiel (MCTS), Apache Airflow (DAG orchestration), Ray DAG.
2. Memory Layer: Context Retention Across Time Horizons
Episodic vs Semantic Memory
Episodic Memory: Context that is session-bound or short-term (e.g., user inputs in the last 5 minutes).
Semantic Memory: Long-term facts, user preferences, and learned insights that persist across sessions.
Design Considerations:
Storage: Episodic memory often lives in Redis or in-context buffers. Semantic memory is stored in vector databases with embedding-based indexing.
Retrieval Pipelines:
Dense Retrieval: Uses embedding similarity.
Sparse Retrieval: Uses keyword matching (BM25, inverted indices).
Hybrid Retrieval: Merges both strategies for better precision.
Memory Management Challenges:
TTL (Time to Live): Prevents memory bloat by expiring stale entries.
Access Control: Restricts access to private memory by role or identity.
Auditability: Every read and write must be traceable, especially in regulated domains.
Tools to Use:
→ Qdrant, ChromaDB, Weaviate (vector DBs), LlamaIndex, Haystack (hybrid search), Loki or ELK Stack for audit logs.
Keep reading with a 7-day free trial
Subscribe to AI with Aish to keep reading this post and get 7 days of free access to the full post archives.