
Dimensions of LLMs: Pre-training, Fine-Tuning, Inference Optimization & More

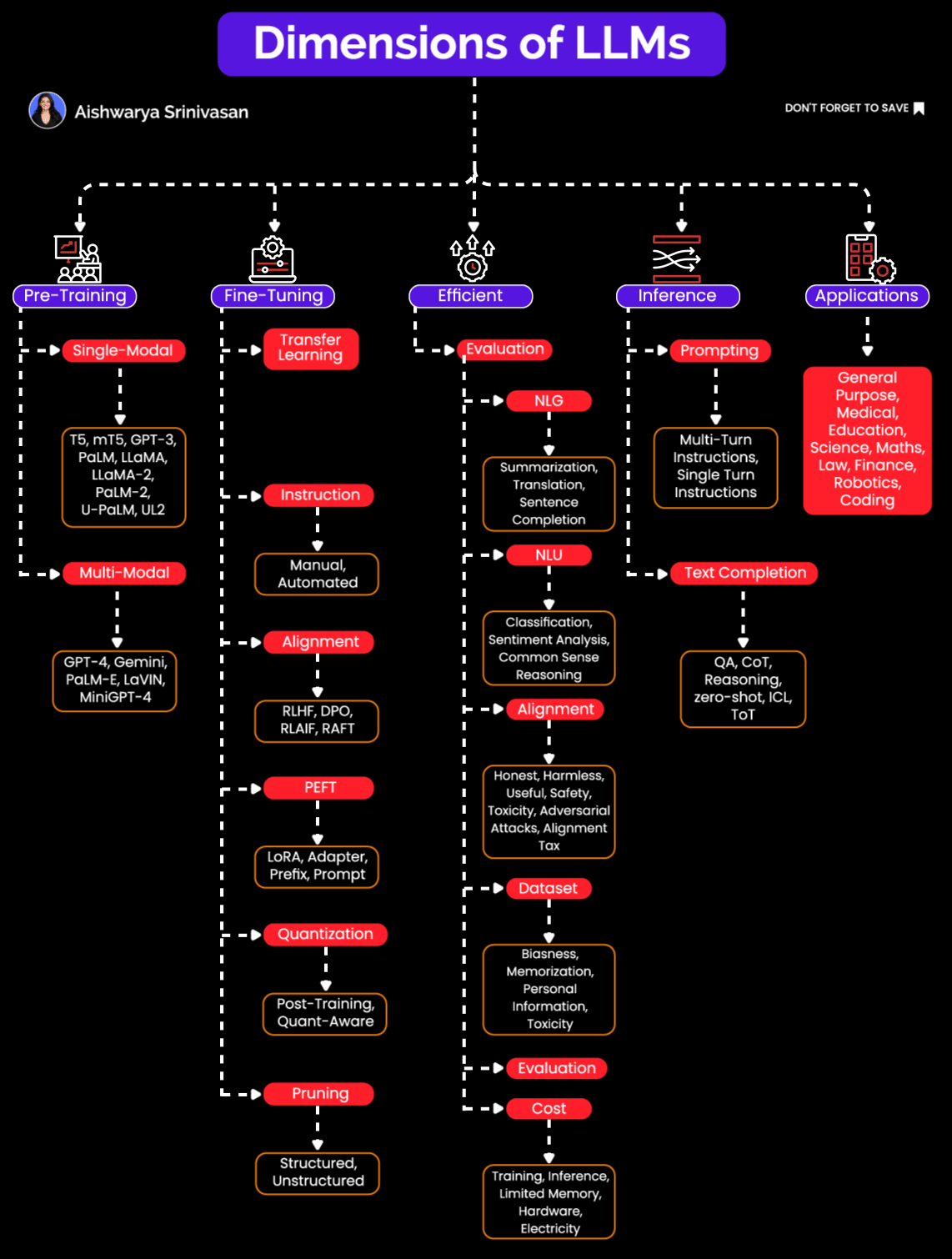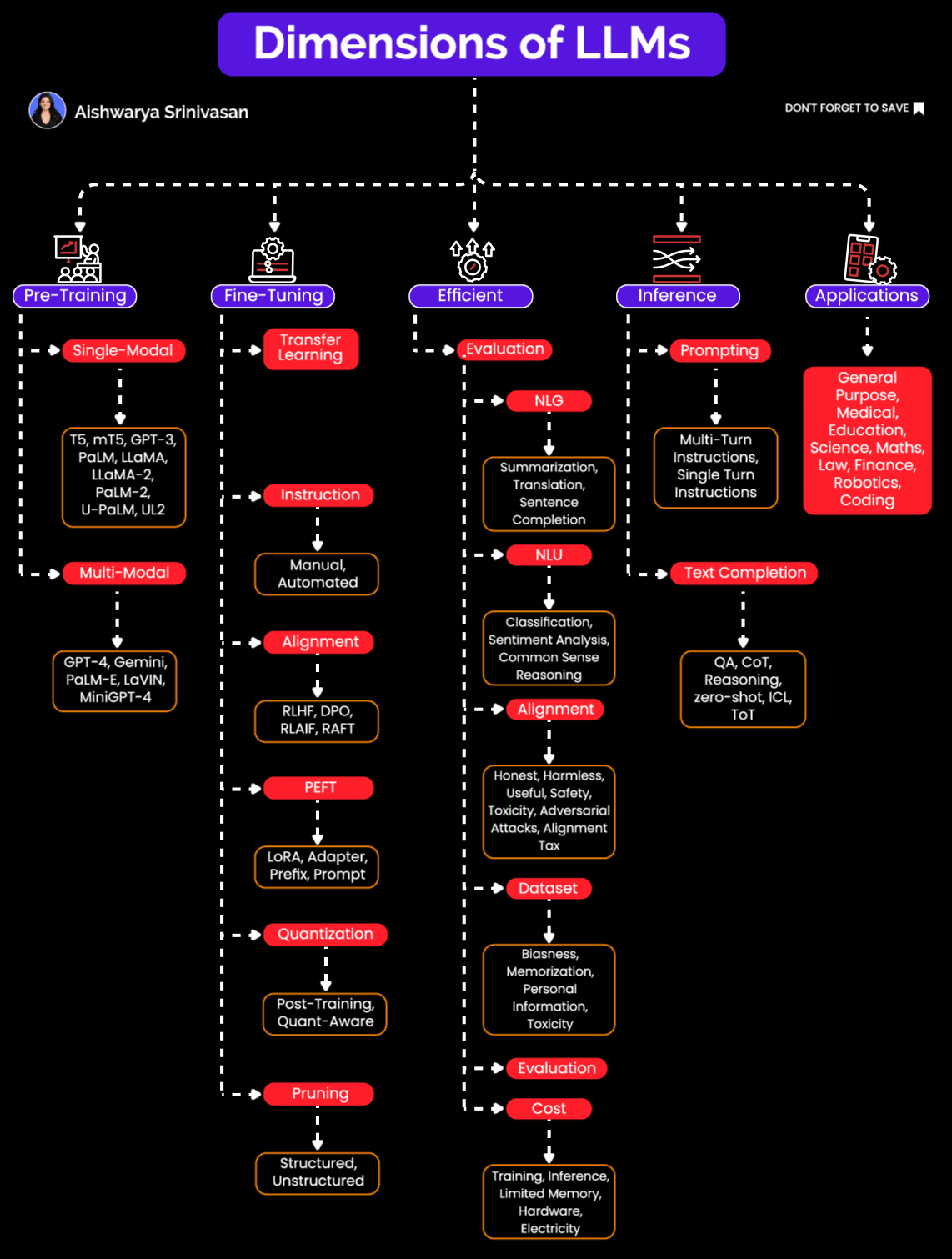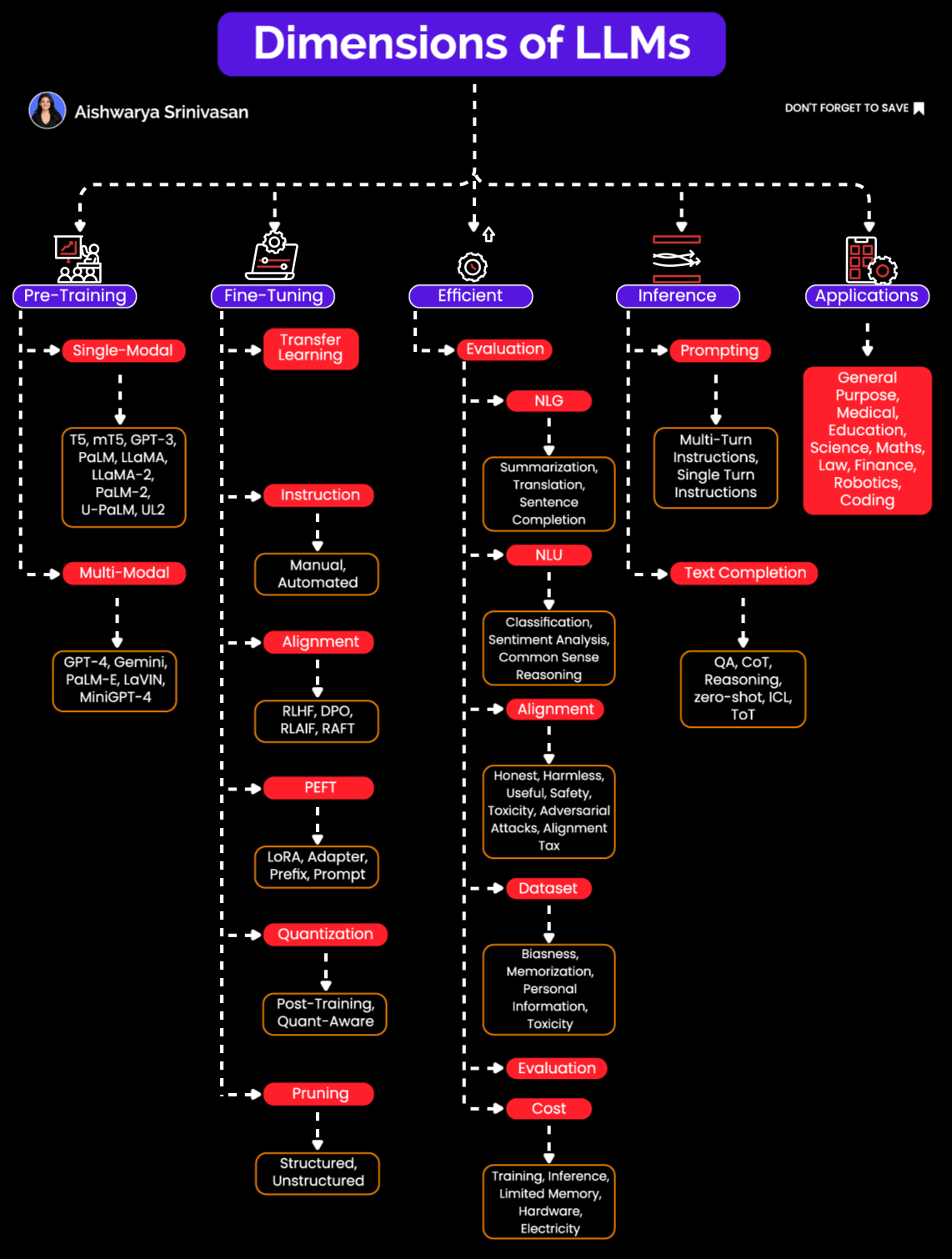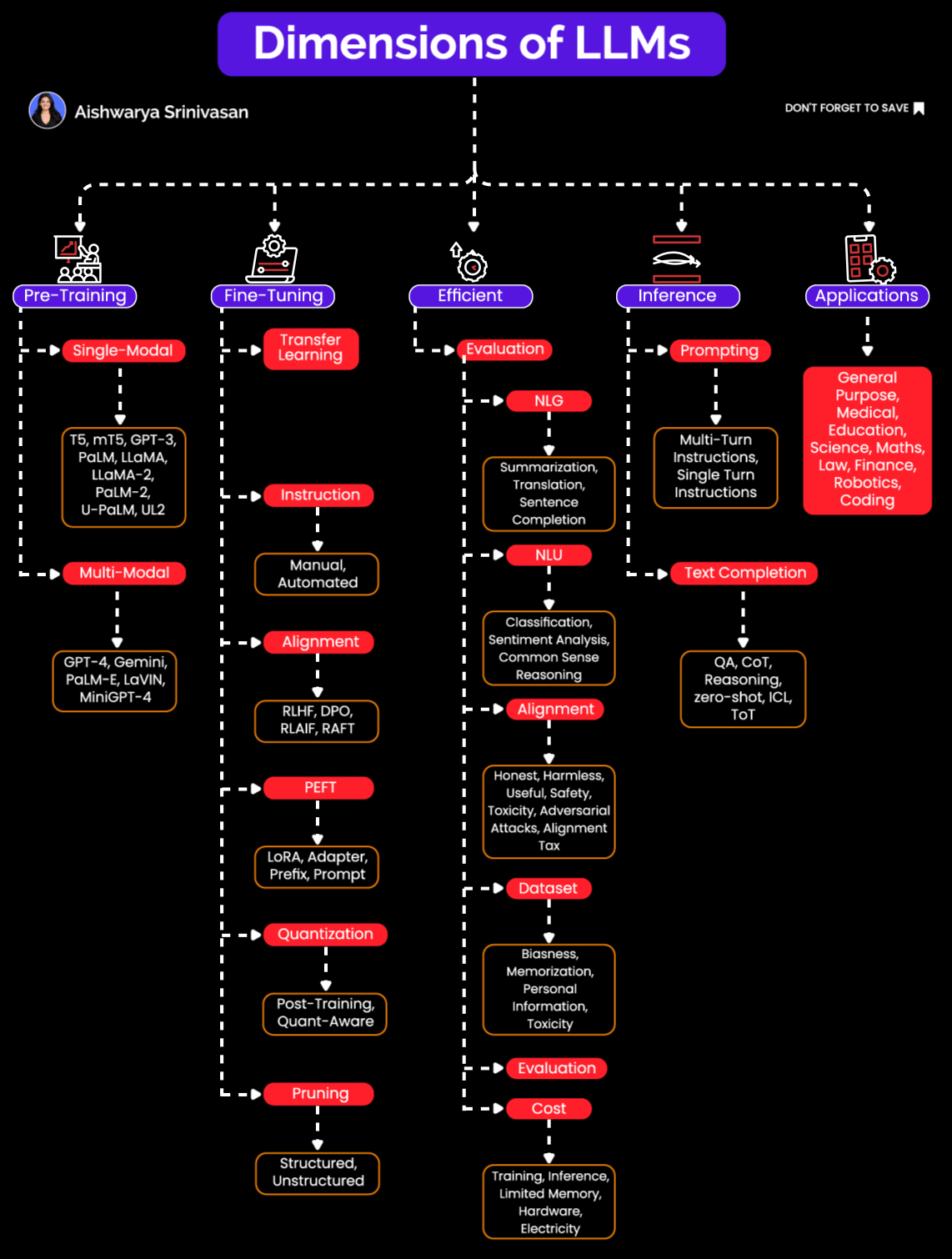
Many AI engineers think of Large Language Models (LLMs) as monolithic "black boxes"- feed a prompt in, and text/code/image comes out. But if you've actually built and deployed these models in production, you know reality is far more nuanced.
LLMs are complex systems requiring careful orchestration across multiple stages: pretraining, fine-tuning, inference, evaluation, and prompting. Treating them merely as standalone models is like viewing a car as "just an engine." Without careful engineering of all parts, the whole thing won't move.
In this post, we will do deep into how LLMs come into existence, and how they evolve into being embedded into scalable GenAI applications.
Pretraining: The Foundation of Intelligence
Pretraining is the first and most foundational stage. This is where the model learns the fundamental patterns of language from vast, diverse datasets. Imagine a child learning to read by devouring every book in a library. That's what pretraining is, the model learns grammar, syntax, world knowledge, and reasoning capabilities by processing petabytes of text and, for multimodal models, images, audio, and more. This stage is incredibly resource-intensive and, for this reason, is typically conducted by large, specialized labs like Google, OpenAI, and Meta. They have the computational power and expertise to build these foundational models.
Architectures and Data
The choice of model architecture is crucial. Most LLMs today are built on the Transformer architecture. The core innovation of the Transformer is its self-attention mechanism, which allows the model to weigh the importance of different words in a sentence, regardless of their position. This is why LLMs can understand long-range dependencies and context so well.
Single-modal models, like the early versions of LLaMA or PaLM, focus on text. Their architectures are optimized with layers for self-attention, feed-forward neural networks, and positional encodings to capture the nuances of sequential text data.
Multimodal models, such as GPT-4 or Gemini, are more complex. They integrate different types of data- text, images, audio, and even video. These models use specialized architectures to handle each modality, such as Vision Transformers (ViTs) for images, and then use cross-attention layers to fuse and align the features from these diverse data sources. The architecture design is a major decision point, as it determines how the model will integrate information from different inputs to form a coherent understanding.
The quality and diversity of the training data are just as important as the architecture. A model trained on a biased or low-quality dataset will inevitably inherit those flaws. Biases in the training data can lead to a model that generates prejudiced or unreliable outputs. High-quality, diverse data is what allows a model to generalize well and produce safe and helpful responses. Pretraining sets the baseline capabilities and limitations of the model, and its scale and cost are why it remains a domain for a few select organizations.
Fine-Tuning: Specialization and Alignment
While pretraining builds a generalist, fine-tuning is where we turn that generalist into a specialist. Fine-tuning takes a pretrained model and adapts it to a specific task or a particular domain. This is the stage where the model becomes useful for real-world applications, whether it's summarizing legal documents, writing marketing copy, or acting as a helpful customer service chatbot.
Parameter-Efficient Fine-Tuning (PEFT)
Full fine-tuning is updating all of a model's parameters, which can be prohibitively expensive and risks "catastrophic forgetting," where the model loses its general knowledge. This is where Parameter-Efficient Fine-Tuning (PEFT) techniques come in.
Low-Rank Adaptation (LoRA) is a popular PEFT method that injects small, trainable matrices into the Transformer layers. It’s highly effective because it only requires training a fraction of the parameters, making it much more memory-efficient and faster.
Prefix Tuning adds trainable, task-specific vectors (or "prefixes") to the input of each layer. These prefixes guide the model toward the desired task without altering the main model weights.
Adapters insert small neural network modules between the layers of the pretrained model. Only the parameters of these adapters are trained, preserving the core model's knowledge.
These methods allow developers to customize models efficiently, but they require careful validation to ensure they don't introduce new, unexpected behaviors in production.
Alignment: Ensuring Safety and Helpfulness
Another critical part of fine-tuning is alignment, the process of ensuring a model’s outputs are helpful, harmless, and aligned with human values.
Reinforcement Learning from Human Feedback (RLHF) is a well-known alignment technique. It uses human feedback to train a separate "reward model" that learns what humans consider a "good" response. The LLM is then fine-tuned using reinforcement learning to generate outputs that maximize the reward model's score.
Direct Preference Optimization (DPO) simplifies this process. Instead of training a reward model, DPO directly optimizes the LLM based on human preference data. This makes alignment simpler and more stable.
Recursive Alignment Fine-Tuning (RAFT) is a more advanced technique that continuously refines a model's alignment through an iterative loop of human feedback. This helps the model maintain its alignment over time and adapt to evolving preferences.
Fine-tuning is where the real differentiation happens. It’s where a generic model becomes a tailored, practical asset with the necessary safety guardrails and domain-specific knowledge to be effective and safe in the real world.
Keep reading with a 7-day free trial
Subscribe to AI with Aish to keep reading this post and get 7 days of free access to the full post archives.