
Operationalizing ML at Scale: Architecting Robust MLOps Pipelines

As AI engineers, we know that the hardest part of building impactful machine learning systems is rarely about squeezing a few extra points of accuracy out of a model. The real bottleneck shows up when moving from research prototypes to production environments: reproducibility, deployment pipelines, monitoring, and scaling. These operational hurdles, not model architecture, are where most AI initiatives stall.
Many organizations discover, often painfully, that a sophisticated model in a Jupyter notebook remains a mere “science project” without foundational capabilities like reproducible training, automated deployments, and post-deployment monitoring. The divide between research prototypes and production-grade ML systems is precisely where Machine Learning Operations (MLOps) plays a pivotal role, enabling organizations to unlock value beyond the build phase.
In 2025, this gap is even more visible. Teams are rushing to productionize large language models, multimodal architectures, and real-time inference systems. Yet many still treat MLOps as an afterthought, which turns promising experiments into brittle deployments. This is why the global MLOps market is projected to reach $19.55 billion by 2032, it’s the backbone of sustainable AI adoption across industries like healthcare, finance, and manufacturing.
This blog breaks down the MLOps maturity journey, highlights technical practices you should adopt, and points to resources for deeper learning.
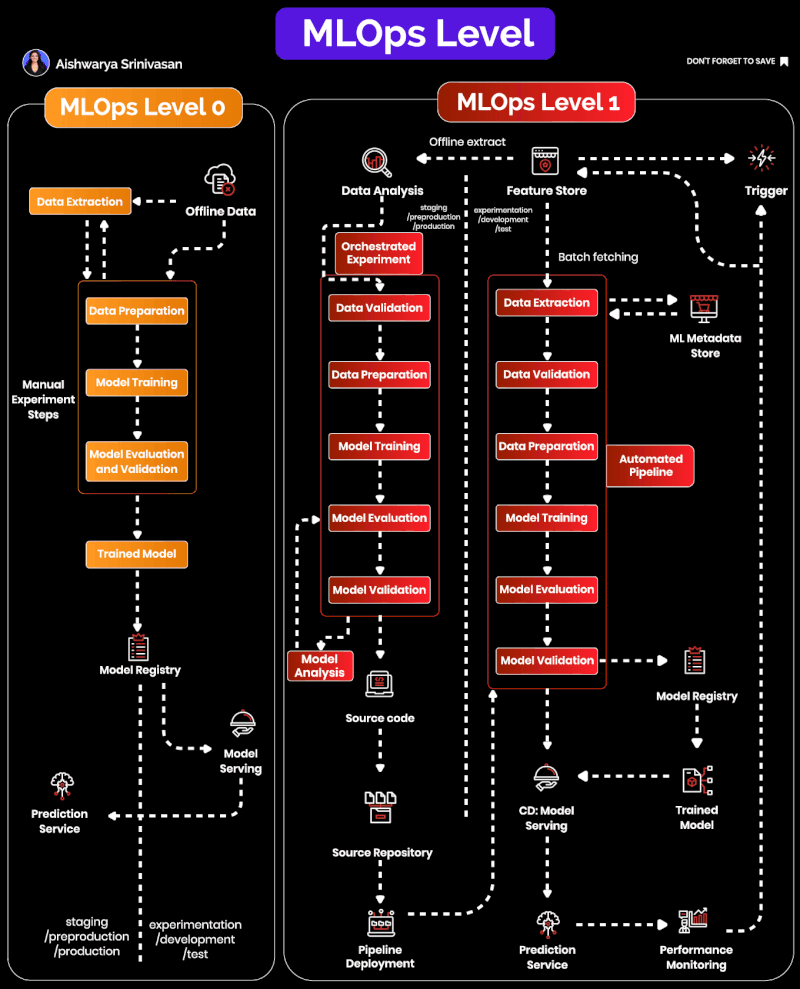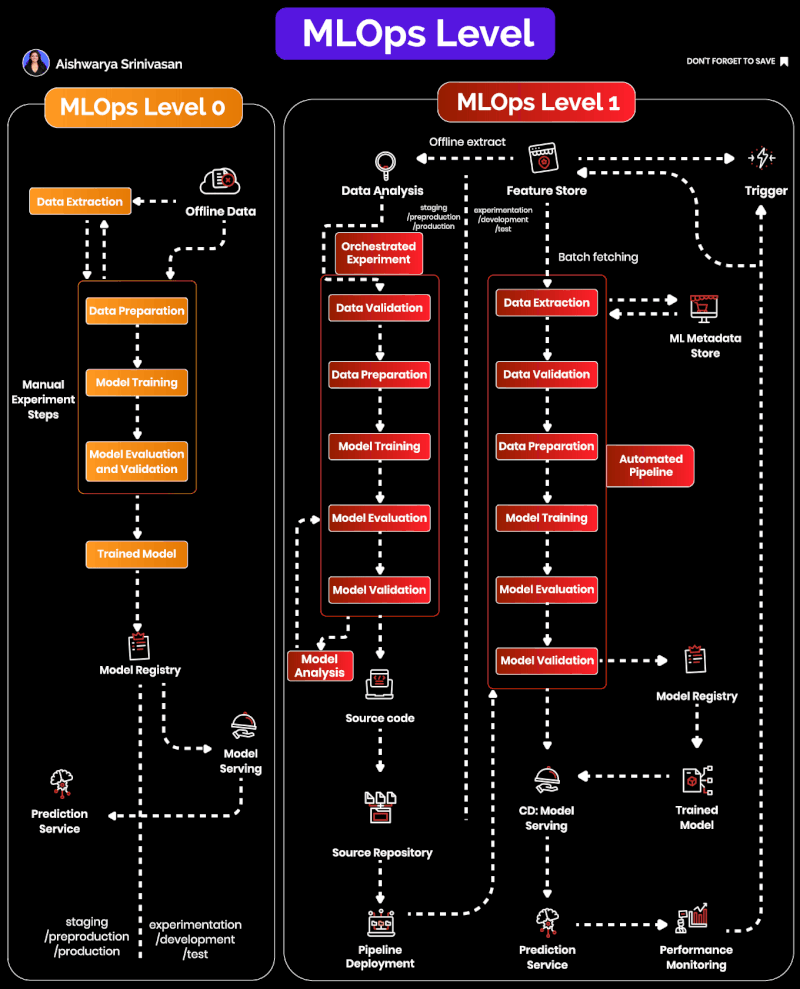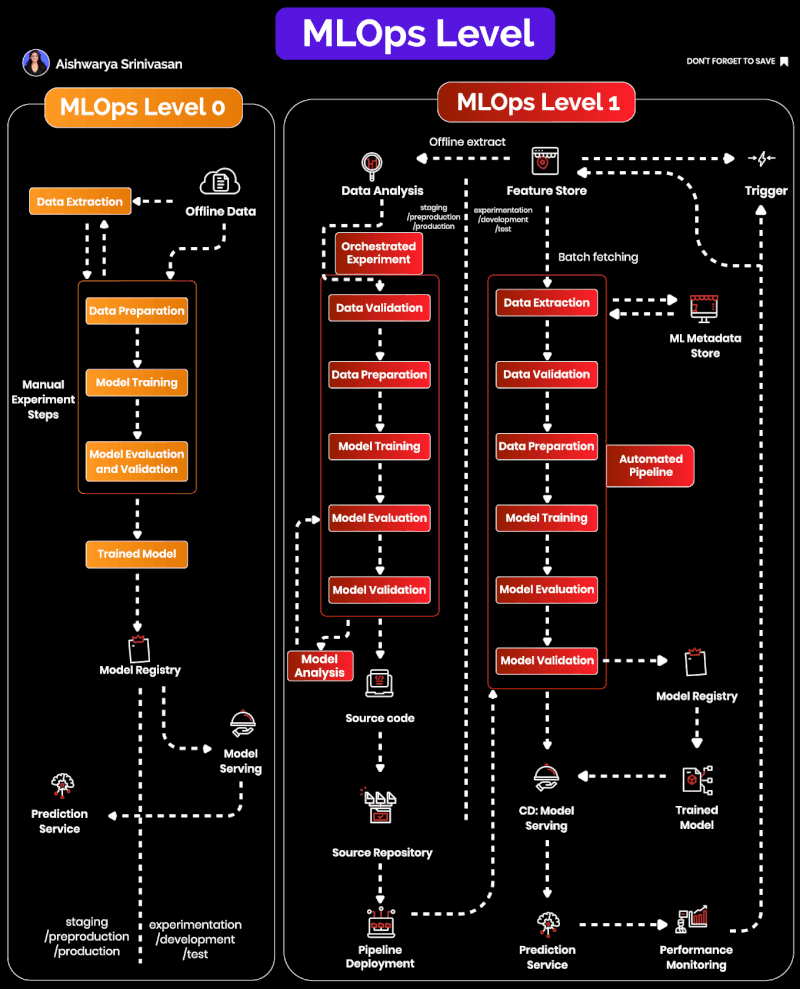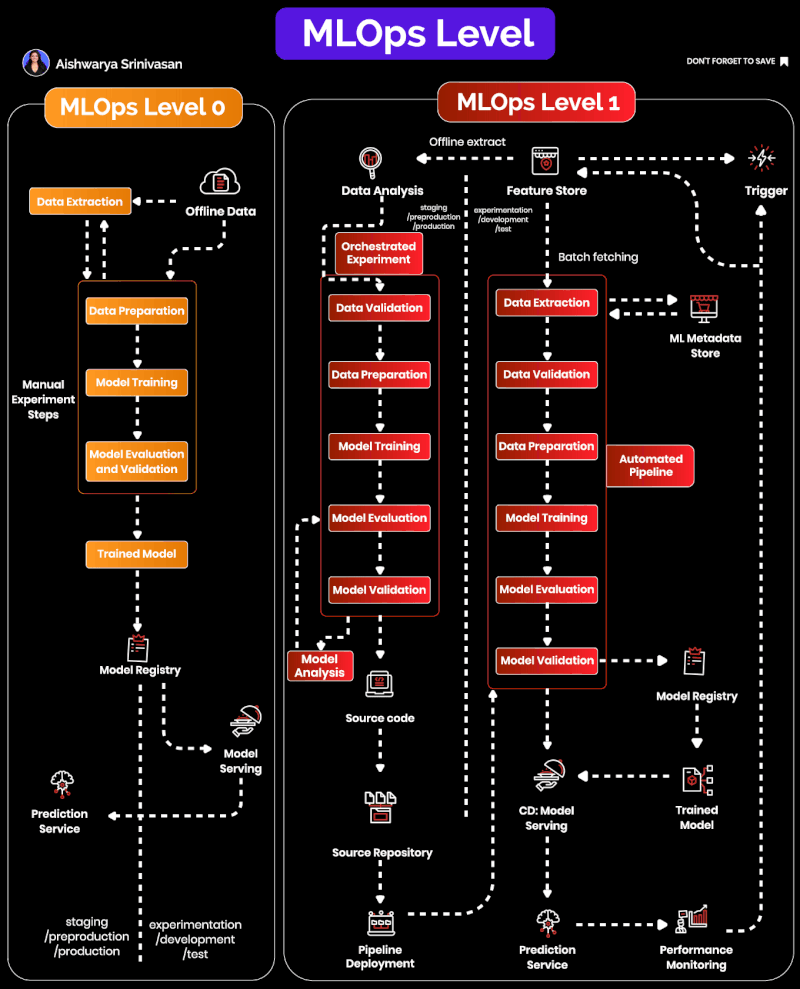
MLOps Maturity Levels
This section uses Google Cloud’s two-level framing: Level 0 (manual experimentation) and Level 1 (pipeline automation). Full CI/CD and continuous training loops belong to later maturity in Google’s taxonomy and are intentionally out of scope here.
Level 0: Manual, Fragile, and Hard to Scale
At Level 0, workflows are manual and inconsistent. Typical symptoms you’ll recognize from real teams:
Execution surface → Ad‑hoc notebooks/scripts on laptops or a single VM, no environment isolation, no pinned CUDA/driver stack, and non‑deterministic builds.
Versioning gaps → Git may exist for code, but datasets, feature definitions, and model artifacts are unversioned. No immutable dataset snapshots; experiments are not reproducible across dev/staging/prod.
Configuration sprawl → Parameters live in notebooks/env vars; no structured config (e.g., Hydra/OmegaConf). Random seeds aren’t fixed; results drift with each run.
Testing is absent → No unit tests around feature transforms; no data‑contract tests; no golden‑set regression tests; no acceptance criteria before serving.
Packaging/serving inconsistencies → Local Python differs from prod image; wheels aren’t pinned; model serialization format isn’t standardized (e.g., mixing pickle/pt/onnx without contracts).
Observability blind spots → No input or prediction logging; no drift checks; no lineage; no SLOs. Failures require forensic debugging.
Security/ops anti‑patterns → API keys in notebooks, broad IAM roles, no secrets manager, no vulnerability scanning of images.
Quick wins to get unstuck (minimal viable rigor):
Repo hygiene → mono‑ or poly‑repo with
pyproject.toml,pre-commit, Makefile, and a baseline Dockerfile; lock dependencies (pip‑tools/Poetry); capture Python/CUDA versions.Experiment tracking → Stand up MLflow or Weights & Biases; log params, datasets (hash/URI), metrics, and artifacts; name runs with semantic model/version.
Data & model versioning → Use DVC/LakeFS to snapshot data and artifacts; store metadata (schema, statistics, checksum) alongside code.
Data contracts → Add Great Expectations/TFDV checks at ingestion; fail fast on schema or distribution violations.
Determinism → Fix RNG seeds, enable framework‑level determinism (e.g., PyTorch cudnn flags), and write a single source of truth config (Hydra).
Observability base → Centralized logging (OpenTelemetry/structured logs) and minimal dashboards for latency, throughput, error rate.
Reference tooling (pick one per row and standardize):
Tracking → MLflow | W&B
Data/artifact versioning → DVC | LakeFS | Quilt
Config → Hydra | OmegaConf
Packaging → Docker | Podman; ONNX | TorchScript; Triton | BentoML
Data validation → Great Expectations | TFDV
Logging/metrics → OpenTelemetry → Prometheus/Grafana
Keep reading with a 7-day free trial
Subscribe to AI with Aish to keep reading this post and get 7 days of free access to the full post archives.