
Why Reasoning is the Key to Building Next-Gen LLM Applications

Let’s call it what it is- most teams are still treating LLMs like overpowered autocomplete engines. One prompt in, one output out. On Repeat.
And yet, the edge in production applications today isn't just in generation, it's in reasoning.
In this post, I break down how reasoning can be scaffolded at inference and training time to build LLMs that go beyond surface-level text generation and actually think. This is where performance, reliability, and scale converge.
Why Reasoning Matters More Than Ever in LLM Applications
Models like GPT-4+ can do more than write well- they can solve, deduce, critique, and adapt. But here’s the catch: this behavior isn’t automatic.
Reasoning has to be scaffolded. Many developers rely on single-shot prompting — asking the model a question and taking the first answer at face value. This approach wastes much of the model’s potential and often results in shallow or incorrect responses. Instead, reasoning involves breaking down problems into intermediate steps, exploring multiple solution paths, and refining answers iteratively. That’s when you move from “looks good” to “is right.”
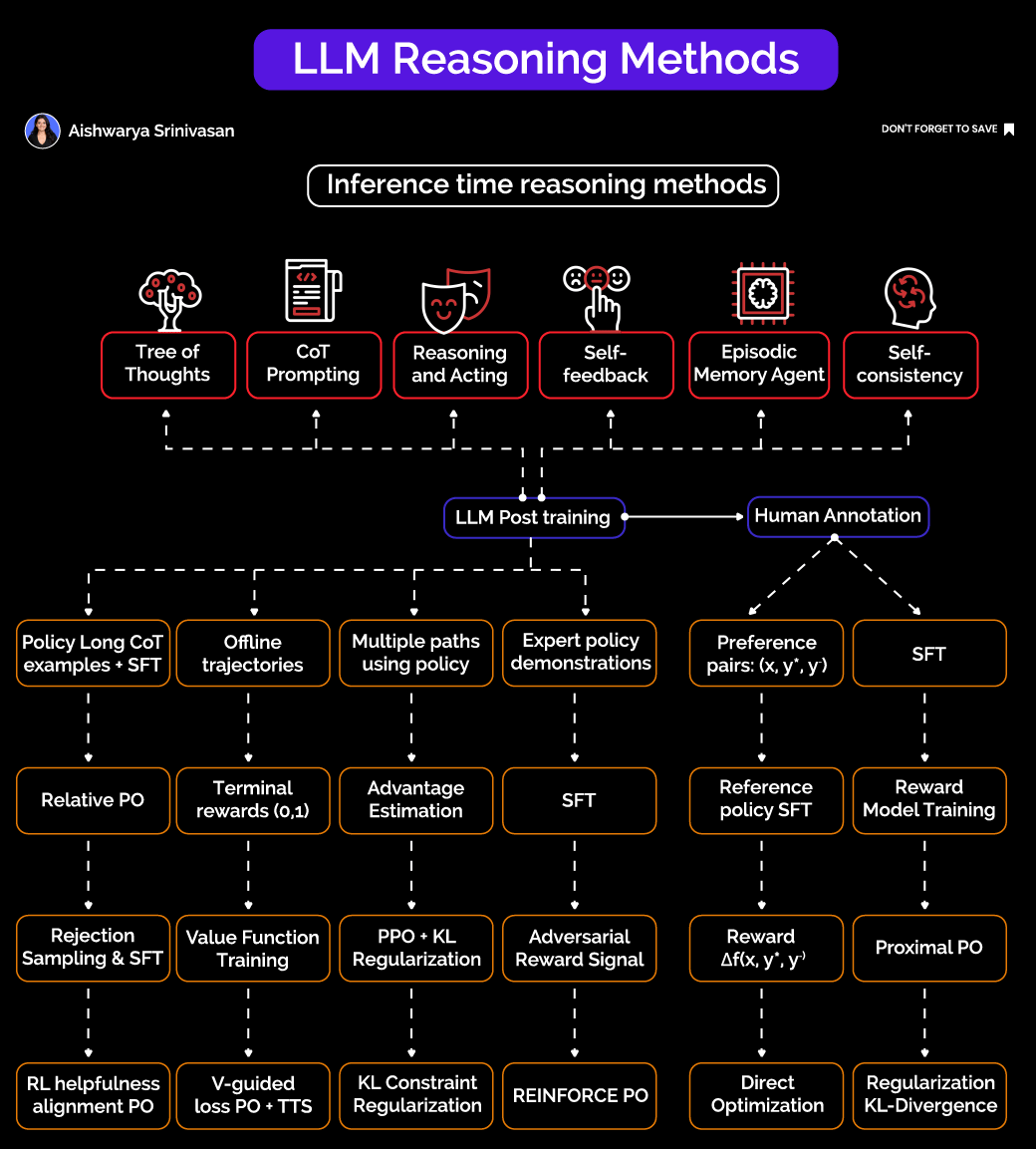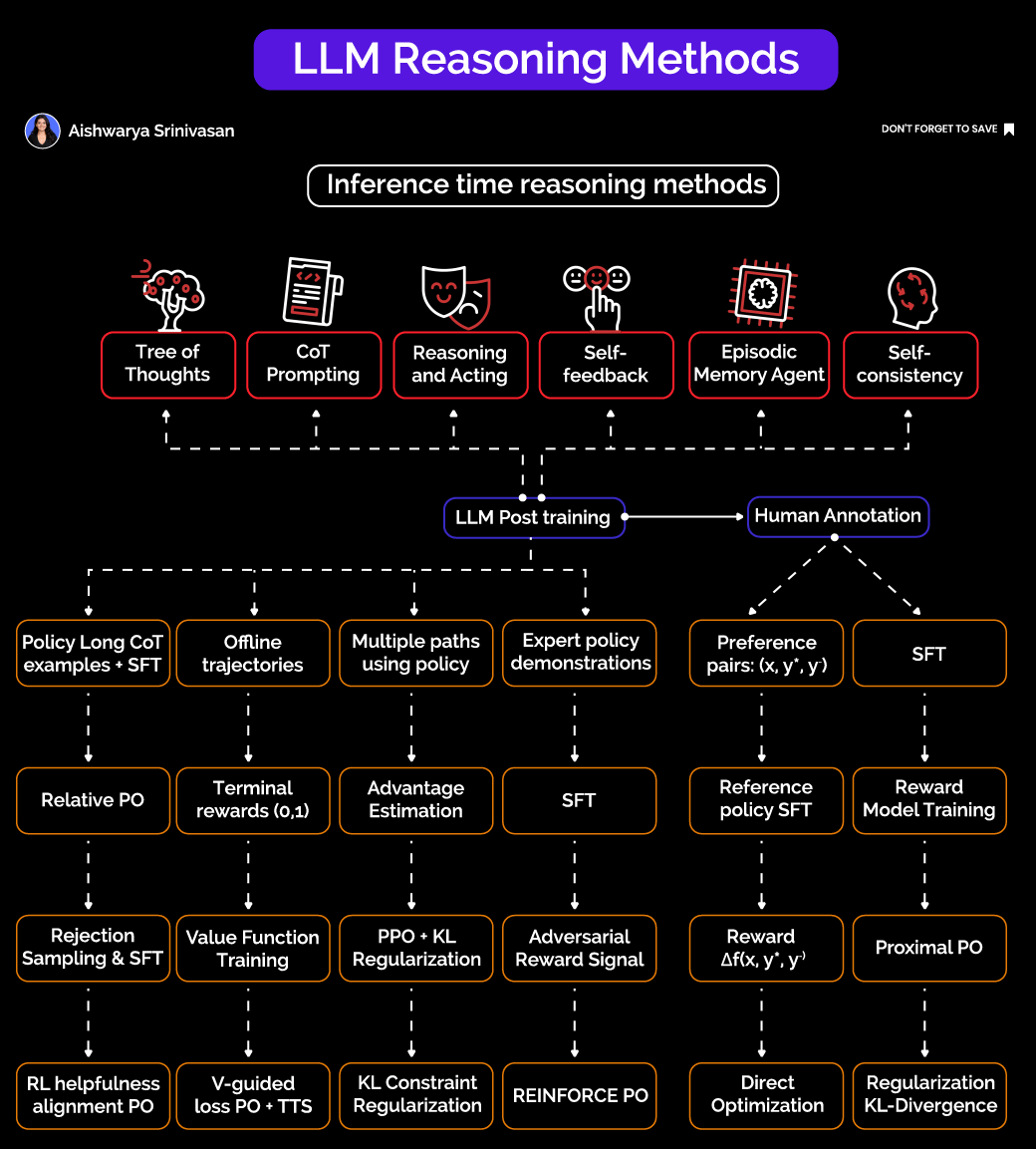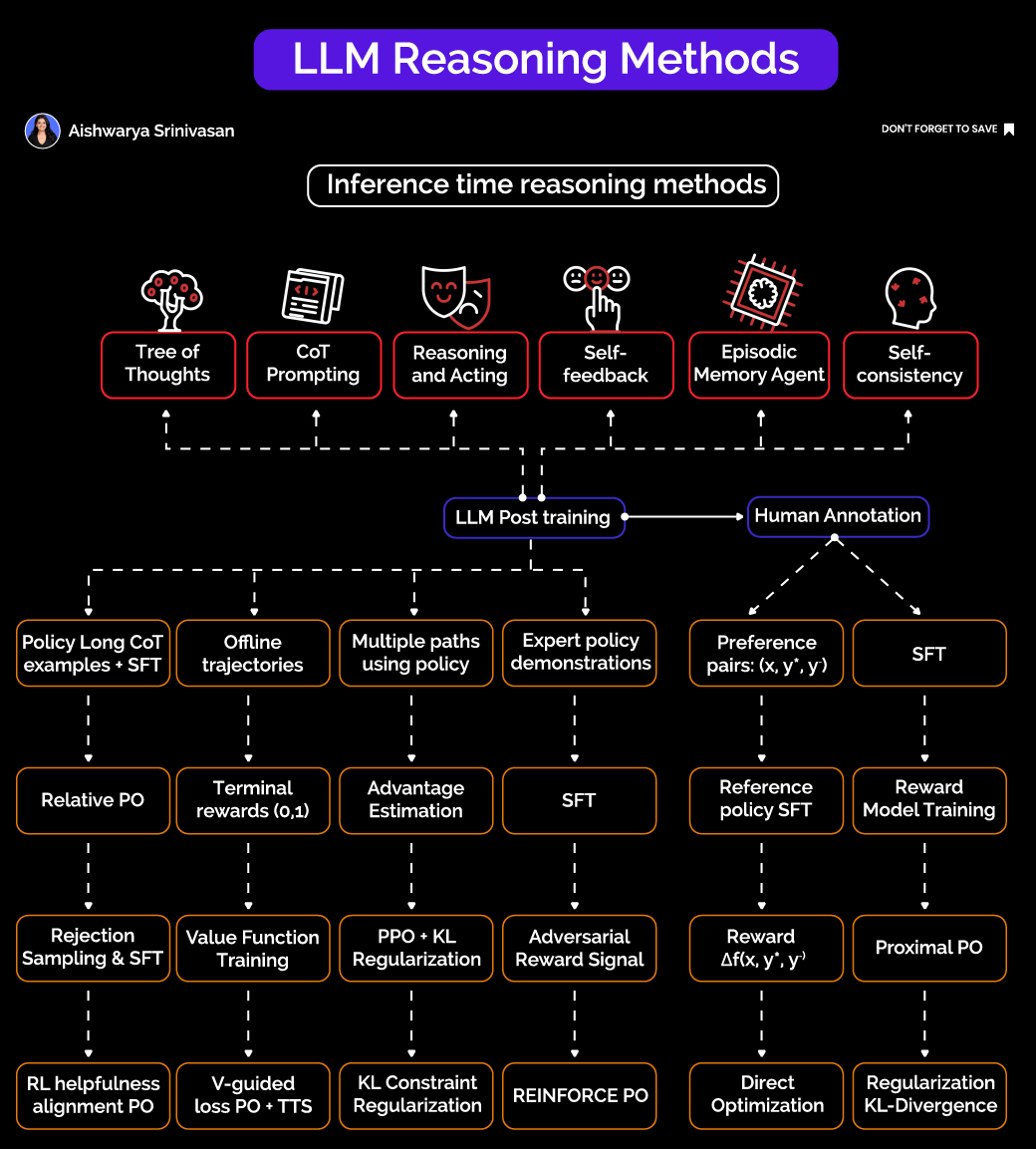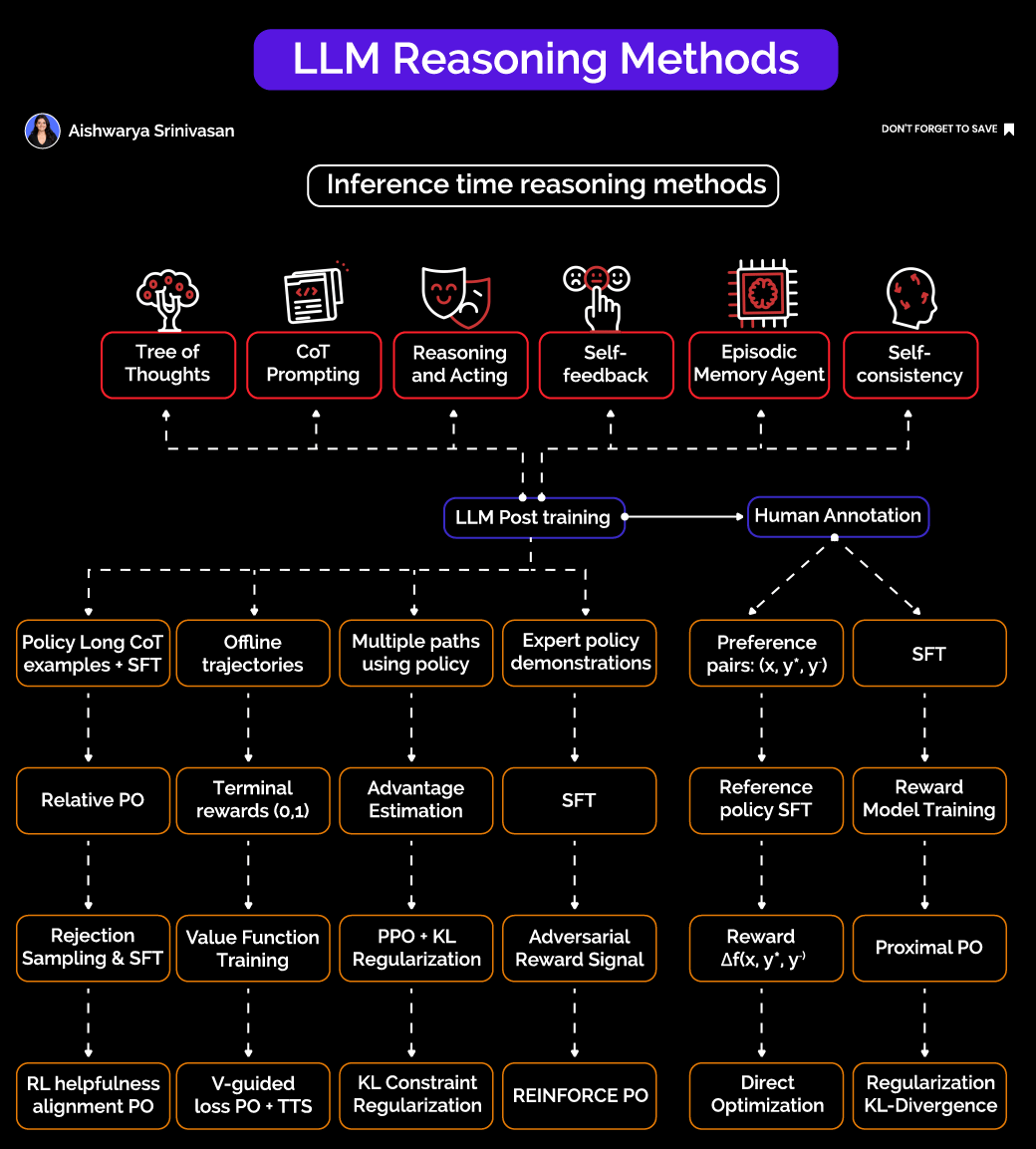
The Two Pillars of LLM Reasoning:
1. Inference-Time Reasoning Methods: Scaffolding (No Retraining Required)
These techniques are applied dynamically when the model generates outputs, without the need for costly retraining or fine-tuning. They include:
Tree of Thoughts (ToT): Instead of generating a single response, the model explores multiple reasoning paths in a tree-like structure, searching for the most promising solution branch.
Chain of Thought (CoT) Prompting: The model is prompted to generate intermediate reasoning steps, effectively “thinking out loud” before arriving at a final answer.
Reasoning + Acting: Combining reasoning with external tools or function calls, allowing the model to interact with APIs or databases during the reasoning process.
Self-Feedback: The model critiques and refines its own outputs, improving answer quality through self-assessment.
Episodic Memory Agents: Maintaining a memory buffer to support multi-step reasoning across interactions.
Self-Consistency: Sampling multiple reasoning paths and selecting the most consistent answer to improve reliability.
These inference-time scaffolds enhance reasoning without significantly increasing latency, making them practical for real-world applications.
2. Post-Training to Align Reasoning Policies
The true power emerges when models are post-trained or fine-tuned to improve reasoning capabilities using human feedback and policy optimization techniques:
Preference Pairs and Reward Models: Models are tuned to prefer better reasoning outcomes based on human annotations or reward signals, using methods like Reinforcement Learning from Human Feedback (RLHF).
Advanced Optimization Techniques: Proximal Policy Optimization (PPO), KL regularization, rejection sampling combined with supervised fine-tuning (SFT), and advantage estimation help guide the model’s policy towards high-quality reasoning.
Exposure to Rich Reasoning Signals: Training on multiple reasoning paths, offline trajectories, and expert demonstrations exposes the model to diverse reasoning patterns, improving generalization.
Emerging methods like Direct Preference Optimization (DPO) and reference-free grading further stabilize and enhance reasoning quality.
Keep reading with a 7-day free trial
Subscribe to AI with Aish to keep reading this post and get 7 days of free access to the full post archives.